


Unveiling the Power of spaCy: A Robust NLP Library for Indonesian
Qurniatullah Hasan
∙15 March 2024

In today's digital age, the fusion of technology and language has paved the way for groundbreaking advancements in Natural Language Processing (NLP). At the heart of this innovation lies machine learning, a powerful computational approach that enables computers to learn patterns and make predictions from data. In this article, we explore the synergy between machine learning, NLP, and spaCy, a robust NLP library that is transforming the landscape of language processing, particularly for the Indonesian language.
Machine Learning: The Backbone of NLP
Machine learning serves as the backbone of NLP, providing the framework for computers to understand, interpret, and generate human language. Through the process of training on large datasets, machine learning algorithms learn to recognize patterns and structures inherent in language, enabling them to perform a wide range of language-related tasks with remarkable accuracy and efficiency. From text classification and sentiment analysis to machine translation and question answering, machine learning empowers NLP systems to extract meaning and insights from textual data.
Natural Language Processing: Bridging the Gap Between Humans and Machines
Natural Language Processing (NLP) bridges the gap between humans and machines by enabling computers to interact with human language in a meaningful way. Through the application of machine learning techniques, NLP systems analyze and process textual data, allowing for tasks such as text understanding, sentiment analysis, and language generation. There are several popular libraries and frameworks in the Python ecosystem for machine learning in natural language processing (NLP). Some of the most commonly used ones include:
- NLTK (Natural Language Toolkit): NLTK is one of the oldest and most widely used libraries for NLP in Python. It provides tools and resources for tasks such as tokenization, stemming, lemmatization, part-of-speech tagging, parsing, and more.
- scikit-learn: While not specifically designed for NLP, scikit-learn includes implementations of many machine learning algorithms that can be applied to NLP tasks. It's particularly useful for tasks like text classification, sentiment analysis, and clustering.
- TensorFlow / Keras: TensorFlow and its high-level API Keras offer tools and modules for building and training deep learning models for NLP tasks. This includes recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer architectures.
- Transformers (Hugging Face): Transformers is a library developed by Hugging Face that provides state-of-the-art pre-trained models for various NLP tasks, including text classification, named entity recognition, machine translation, and more. It's based on transformer architectures like BERT, GPT, and RoBERTa.
- PyTorch: PyTorch is another popular deep learning library that provides flexible tools for building and training neural networks. It's widely used in research and industry for NLP tasks, offering support for building custom architectures and experimenting with new ideas
- spaCy: spaCy is a modern and efficient library for NLP in Python. It's known for its speed and ease of use, offering pre-trained models for various NLP tasks such as named entity recognition, part-of-speech tagging, dependency parsing, and more.
These are just a few examples, and there are many other libraries and tools available for NLP in Python.
Introducing spaCy: A Game-Changer in Indonesian NLP
Enter spaCy, spaCy is a popular open-source library for natural language processing (NLP) in Python. It's designed to be fast, efficient, and user-friendly, making it suitable for both research and production environments.
spaCy is a powerful and versatile NLP library that is revolutionizing language processing for the Indonesian language. Built on the principles of efficiency, accuracy, and ease of use, spaCy offers a comprehensive suite of tools and functionalities tailored to meet the unique challenges of Indonesian NLP. From tokenization and part-of-speech tagging to named entity recognition and dependency parsing, spaCy empowers developers, researchers, and language enthusiasts to unlock the full potential of Indonesian text data.
spaCy offers a range of features that make it ideal, including:
- Tokenization: spaCy can split Indonesian text into tokens, such as words, punctuation, and named entities.
- Part-of-speech tagging: spaCy can assign each token a part-of-speech (POS) tag, such as noun, verb, or adjective.
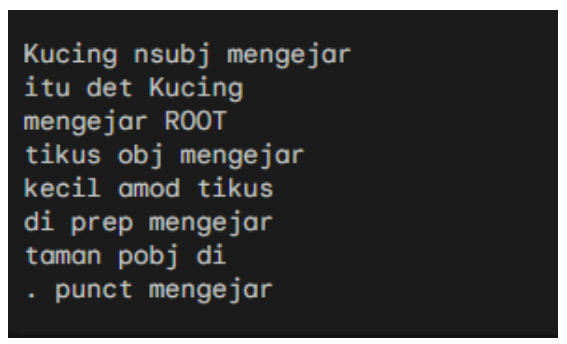
- Dependency parsing: spaCy can build dependency structures for sentences, showing the relationships between words.
- Named entity recognition: spaCy can identify named entities such as people, places, and organizations.
- Text classification: spaCy can be used to classify text into specific categories, such as sentiment, topic, or intent.
Benefits of using spaCy:
The benefits of using spaCy for natural language processing (NLP) include:
- Efficiency and Speed: spaCy is known for its speed and efficiency, making it suitable for large-scale information extraction tasks.
- Industrial-Strength NLP: It is designed for production use, enabling the development of applications that process and understand large volumes of text.
- Granular Approach: Unlike NLTK, spaCy is known for its granular approach to NLP, providing fast and accurate syntactic analyses and access to larger, customizable word vectors.
- Easy Integration and Productivity: spaCy is easy to install and has a simple and productive API, making it suitable for real-world NLP applications.
- Memory Management: It is written in carefully memory-managed Cython, contributing to its efficiency and speed.
- Support and Ecosystem: Since its release in 2015, spaCy has become an industry standard with a huge ecosystem, offering various plugins and integration with machine learning stacks.
Step by step using spaCy:
To use the Indonesian language model in spaCy, you need to download and install the id_core_web_sm model. Here are the steps to follow:
-
Installation: Install spaCy using pip or conda. For example, you can use the following commands: pip install -U spacy
-
Download the Indonesian Language Model: Download the id_core_web_sm model using the following command: python -m spacy download id_core_web_sm
-
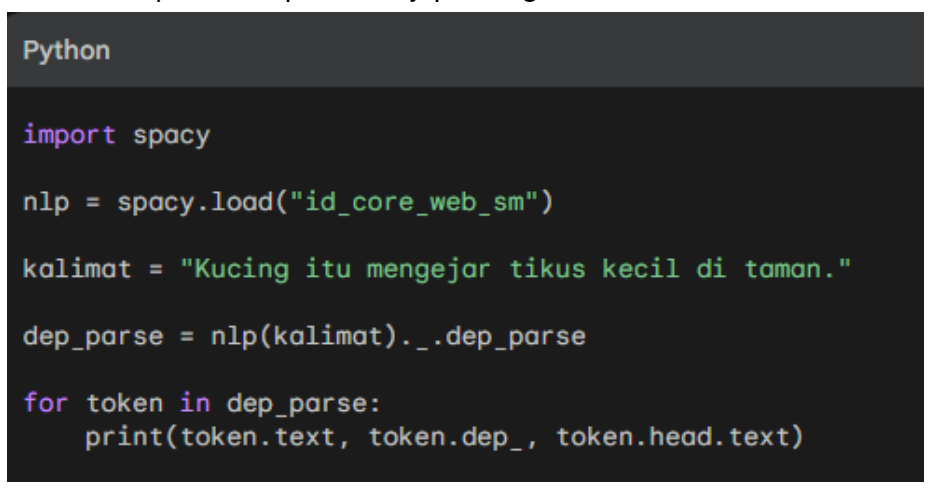
Import and Load: Import the spaCy library and load the language model. For example, to load the Indonesian language model, you can use the following Python code: import spacy nlp = spacy.load("id_core_web_sm")
Example 1: Named Entity Recognition
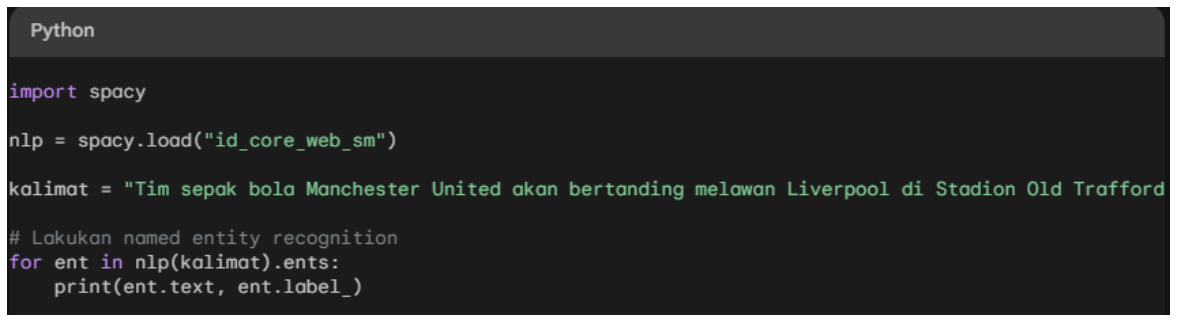 Output:
Output:
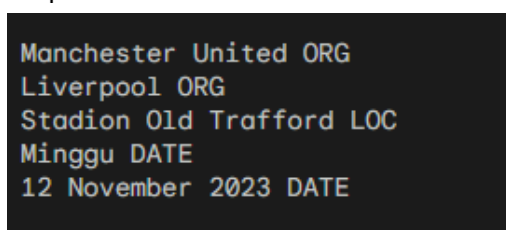 Example 2: Named Entity Sentiment
Example 2: Named Entity Sentiment
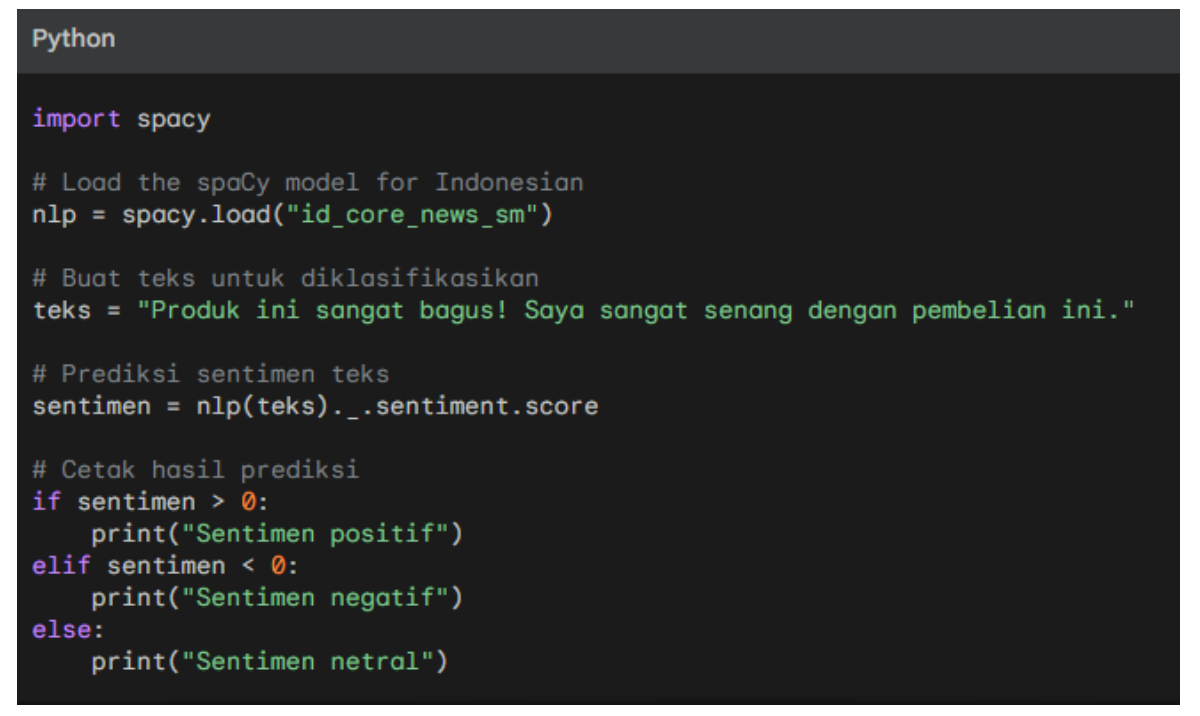 This code will print "sentimen positif" because the given text has a positive sentiment.
This code will print "sentimen positif" because the given text has a positive sentiment.
Example 3: Tokenization
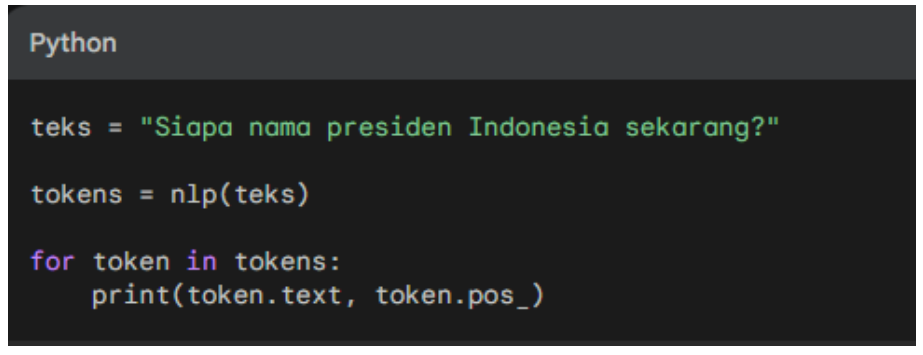
Output:
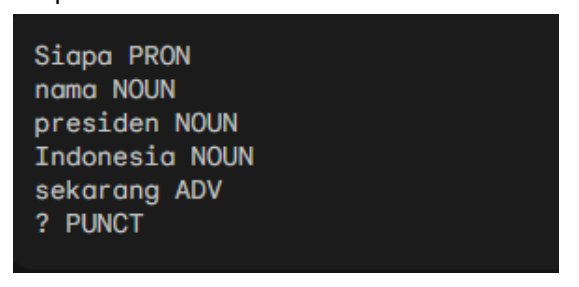 Example 4: Dependency parsing
Example 4: Dependency parsing
Output:
Conclusion
The spaCy library is a powerful and efficient tool for natural language processing (NLP). It offers a wide range of features, including a fast and accurate syntactic dependency parser, named entity recognition, and support for various languages, including Indonesian. The library is designed for industrial-strength NLP applications, making it suitable for production use. Additionally, spaCy provides easy integration, a rich API for linguistic features, and the ability to disable specific components to improve processing speed. Its performance is attributed to the fact that it was written in Cython from the ground up, and it offers access to larger, customizable word vectors. Overall, spaCy is a popular choice for NLP practitioners and researchers due to its speed, efficiency, and robust capabilities
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara