


Unlocking the Power of Machine Learning with PyCaret: A Game-Changer in Automated ML
Hieremias Kevin Juwantoro
∙19 March 2024

In the ever-evolving field of machine learning, developers are constantly seeking tools and frameworks that streamline the model building process. Machine learning (ML) has become an integral part of various sectors, ranging from finance and healthcare to marketing and manufacturing. As the demand for ML solutions continues to grow, so does the need for tools that can streamline the development and deployment of ML models. One such tool that has gained significant attention in recent years is PyCaret. In this article, we will explore the profound benefits that PyCaret brings to the table, its limitations, and highlight why it is a must-know tool for machine learning enthusiasts and professionals alike.
Problem Statement
Developing accurate and efficient machine learning models can be a labour-intensive and time-consuming task. This hurdle often discourages beginners and even seasoned practitioners from effectively utilizing machine learning techniques to their full potential. The need for a comprehensive and user-friendly framework to simplify the machine learning workflow. PyCaret, with its ability to automate the entire ML pipeline, presents itself as a compelling solution to address this challenge.
At its core, PyCaret is an open-source Python library that simplifies the end-to-end machine learning process. With a wide range of pre-processing techniques, model selection algorithms, and ensemble methods, PyCaret empowers both beginners and experts to efficiently train, evaluate, and deploy high-performing machine learning models.
PyCaret enables users to perform complex machine learning tasks with a few lines of code, making it an ideal choice for researchers, data scientists, and business professionals seeking to unlock the potential of their data. By leveraging PyCaret's automated ML capabilities, users can save countless hours typically dedicated to data cleaning, feature extraction, model selection, and hyperparameter tuning , freeing up valuable time for advanced analysis and model enhancement.
Step by Step Using PyCaret
1. Pip Install PyCaret
You can also install it while using a notebook by running the following code.
pip install pycaret
2. Load Dataset
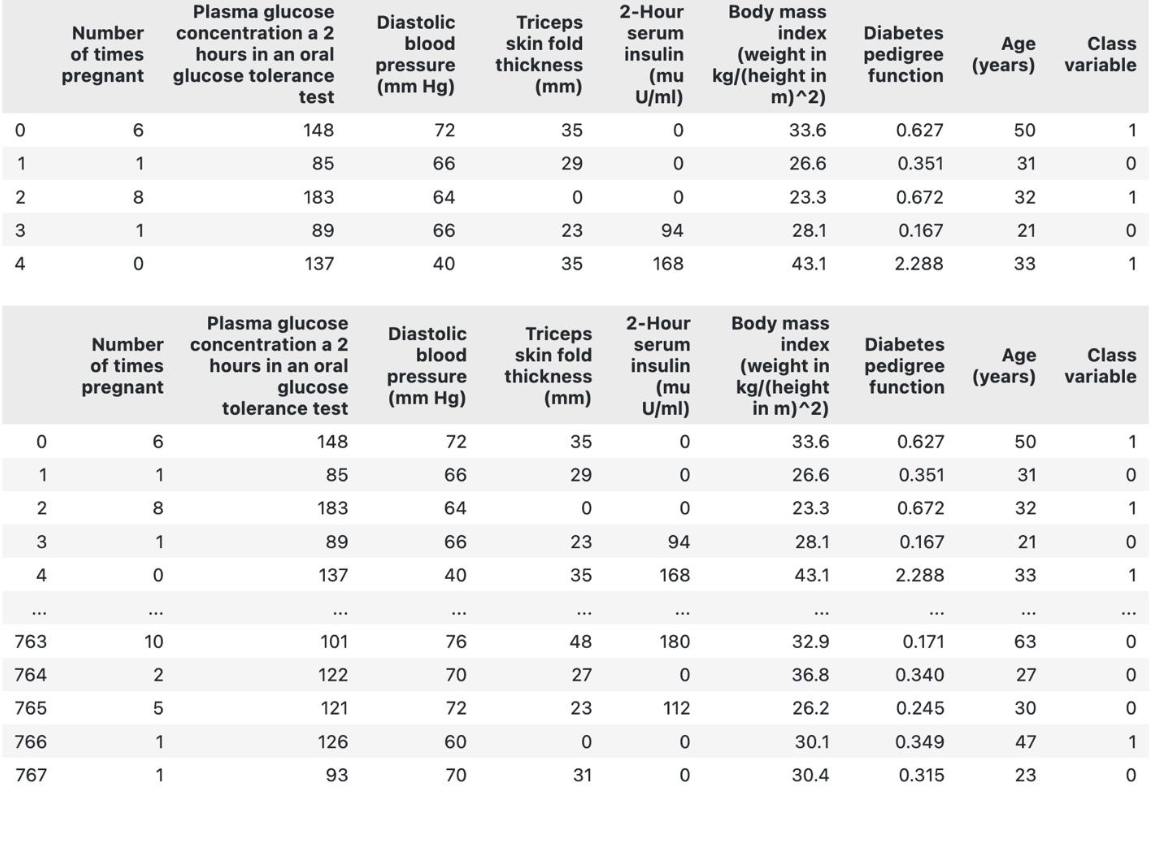
You can use datasets available in the PyCaret repository or your own datasets to train the model. If you want to use your own dataset, use a pandas data frame to import the CSV file from the reference source. For this article, I’am using dataset that are provided by Pycaret named diabetes
from pycaret.datasets import get_data
data = get_data('diabetes') data
3. Setting up Environment
Setting up the environment for machine learning can be a tedious task, involving the installation and configuration of various libraries and dependencies. However, PyCaret simplifies this process by providing a single command to install all the required libraries. It ensures that the necessary environment setup is consistent across different platforms, making it easier to collaborate and share machine learning projects.
#For Classification from pycaret.classification import *
#For Regression from pycaret.regression import *
#For Clustering from pycaret.clustering import *
#For Anomaly Detection from pycaret.anomaly import *
#For Time Series from pycaret.time_series import *
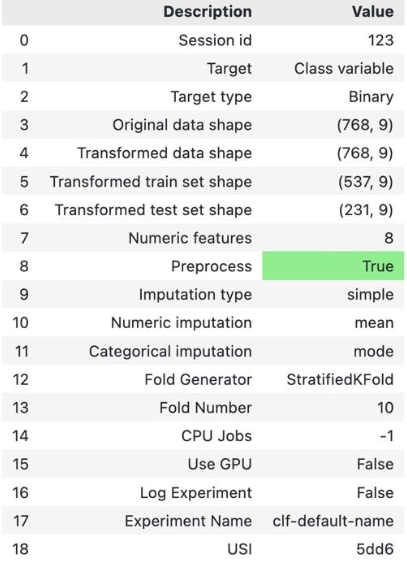
We can perform our own pre-processing steps such as removing empty rows, dropping columns, and so on. However, as I mentioned earlier, PyCaret provides its own data pre-processing process using parameters within the setup() function. Once this function is imported, we then define the training dataset and its target class, which is the "Class variable" column. I split the dataset with a ratio of 80% for training data and 20% for testing data.
from pycaret.classification import *
from sklearn.model_selection import train_test_split
train, test = train_test_split( data, test_size=0.2, random_state = 42)
#Set up your experiment exp = setup(data, target='Class variable', session_id=123)
4. Compare Model
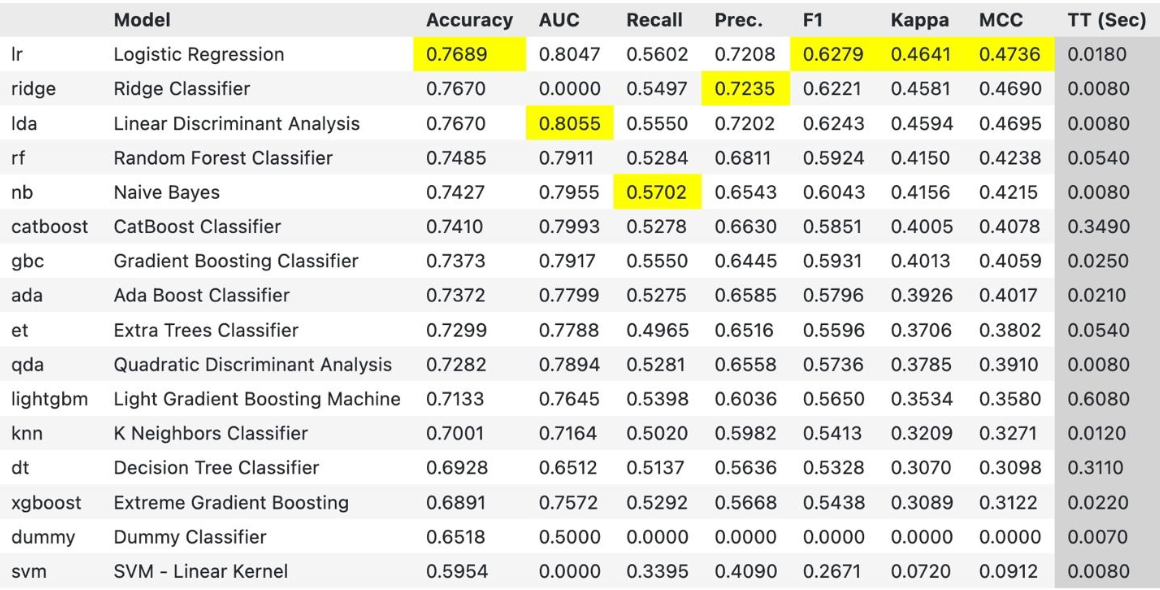
Comparing the performance of different models is crucial for selecting the best algorithm for a given problem. PyCaret automates this process by comparing the performance of various models on a given dataset using cross-validation. It provides insightful visualizations and metrics that allow data scientists to make informed decisions about which models to further experiment with.
#Train and tune the model best_model = compare_models()
Building machine learning models can be a complex and time-consuming process. PyCaret simplifies this by providing a vast collection of pre-implemented machine learning algorithms that cover a wide range of problem types. It abstracts away the complexities of algorithm implementation, allowing data scientists to quickly train and evaluate models with just a few lines of code.
5. Hyperparameter Tuning
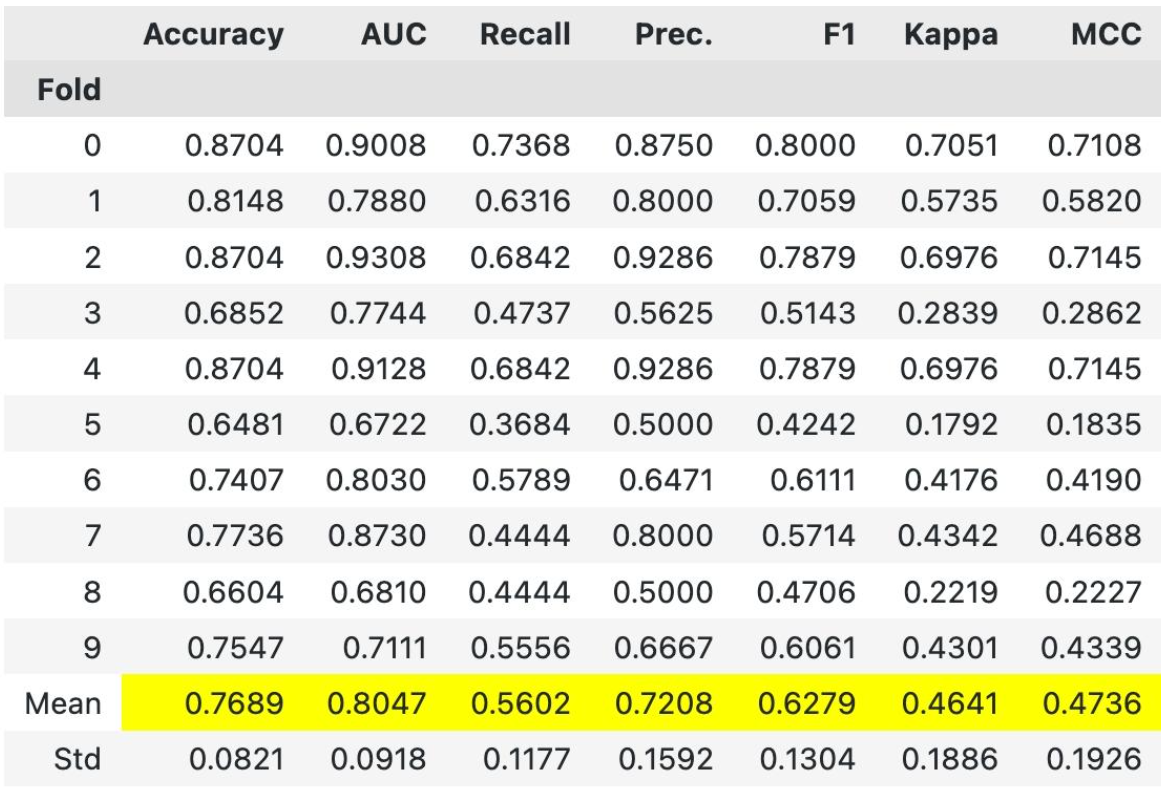
Hyperparameter tuning is another essential step in optimizing the performance of machine learning models. PyCaret offers different techniques, such as grid search and random search, to find the optimal hyperparameters for each algorithm. It automates this process, reducing the manual effort required for hyperparameter tuning and enabling data scientists to find the best model configuration effortlessly.
#Tune the best model
tuned_model = tune_model(best_model)
6. Evaluation model with Visualization
Model Evaluation after Tuning: After performing tuning, you evaluate your model using the evaluate_model() function. This function will generate a number of visualizations useful for analyzing evaluation results. These include confusion Matrix and Other Visualization that help you understand the prediction quality of the model.
#Evaluate the tuned model
evaluate_model(tuned_model)
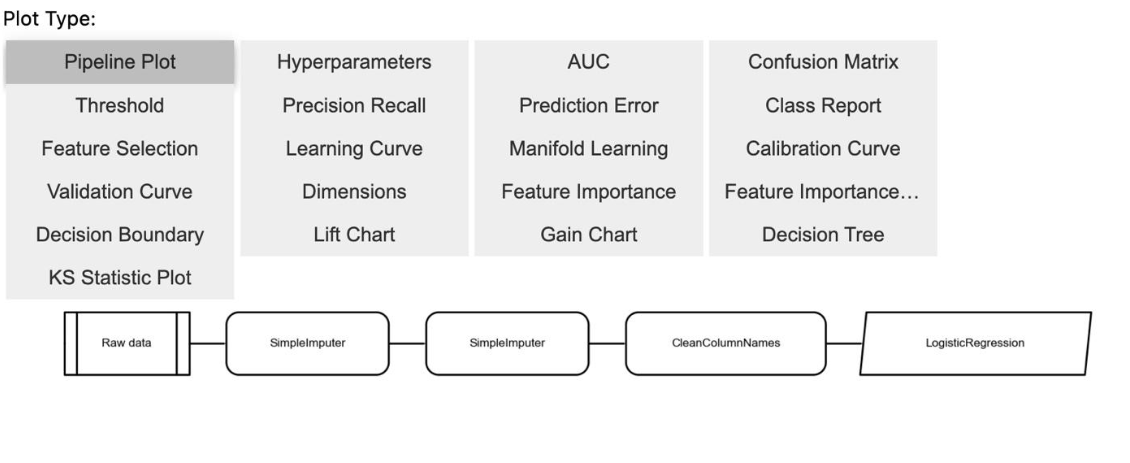
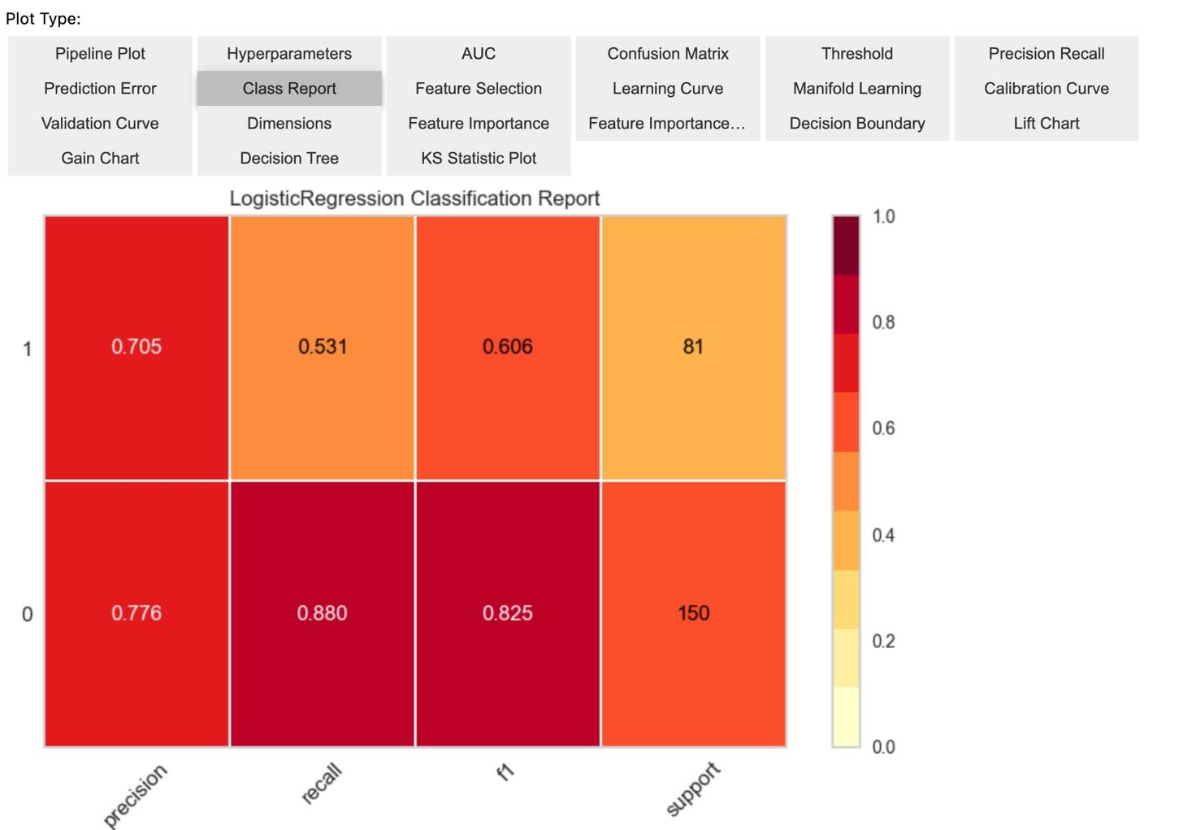
7. Predictions with Tuned Model
After obtaining the tuned model, you can use it to make predictions on new data using predict_model().
#predict (test data) predictions = predict_model(tuned_model, data = test)

8. Save the Final Model
Saving the model is essential for reusing the trained model for future predictions and sharing it with others. PyCaret provides a simple yet powerful mechanism to save and load the trained model, preserving the entire pipeline along with pre-processing steps. This ensures that the model can be used consistently in different environments and deployments.
Key Benefits of PyCaret
-
Streamlined ML Workflow: PyCaret offers a simple and intuitive API that accelerates the development and deployment of ML models. Its automated pipeline eliminates the need for manual intervention during various steps, ensuring faster iterations and experimentation.
-
Comprehensive Pre-processing: PyCaret provides a suite of pre-processing techniques, enabling users to handle missing values, categorical variables, and feature scaling effortlessly. This reduces the burden of creating custom pre-processing pipelines, allowing users to focus on model creation and evaluation.
-
Automated Model Selection: PyCaret automates the process of hyperparameter tuning and algorithm selection, making it easier to identify the best model for a given dataset. It evaluates multiple algorithms with cross-validation automatically, providing insights into model performance and facilitating faster decision-making.
-
Rich Visualization Capabilities: PyCaret's built-in visualization library simplifies the exploration and understanding of complex data sets. From interactive analysis to feature importance plots, users can gain valuable insights into their data seamlessly.
Limitations and Weaknesses
Like any tool, PyCaret has certain limitations. While it supports a wide range of machine learning algorithms and pre-processing techniques, some advanced or niche techniques may not be readily available. Additionally, PyCaret's automated approach may oversimplify complex problems, limiting the control and customization options for experienced machine learning practitioners.
Conclusion
In conclusion, PyCaret is a remarkable tool that empowers both beginners and professionals to harness the power of machine learning without getting lost in the technical complexities. It simplifies the machine learning workflow, enables quick experimentation, and aids in the deployment of robust models. Despite its limitations, PyCaret serves as a valuable asset in the arsenal of any machine learning enthusiast, acting as a catalyst for democratizing the field.
By leveraging PyCaret's automation, organizations can reduce the barrier to entry for machine learning, foster innovation, and unlock new use cases. As the machine learning landscape continues to evolve, embracing tools like PyCaret will undoubtedly shape the success of future generations of data scientists and revolutionize the way we approach complex problem-solving.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara