


Tutorial ETL: Menggunakan Python untuk Membersihkan dan Mengunggah Data dari Database ke Google Drive
Fadhel Ijlal Falah
∙15 March 2024

ETL (Extract, Transform, Load) adalah suatu proses yang penting dalam pengelolaan data yang terdiri dari tiga tahapan utama: Ekstraksi, Transformasi, dan Pengisian. Proses ini digunakan untuk mengambil data dari satu atau beberapa sumber, mengolahnya, dan menyimpannya ke suatu lokasi yang lebih berguna seperti penyimpanan data atau warehouse.
Definisi ETL:
-
Ekstraksi (Extract): Tahap pertama dari ETL adalah ekstraksi, di mana data diambil dari sumber eksternal seperti database, file, atau aplikasi lainnya. Data diekstraksi dengan mengakses sumber data yang ada dan menyalinnya ke tempat penyimpanan sementara.
-
Transformasi (Transform): Tahap berikutnya adalah transformasi, di mana data yang diekstraksi diproses, dibersihkan, dan diubah ke dalam format yang diperlukan. Transformasi ini dapat mencakup manipulasi struktur data, pembersihan data, atau perhitungan tambahan.
-
Pengisian (Load): Tahap terakhir adalah pengisian, di mana data yang telah diolah dan disiapkan di-load atau dimuat ke dalam penyimpanan data yang dituju seperti warehouse atau database.
Kapan kita harus menggunakan ETL? ETL biasanya digunakan ketika kita perlu:
-
Menggabungkan Data dari Berbagai Sumber: Ketika data yang dibutuhkan terletak di beberapa sumber yang berbeda, seperti database relasional, file CSV, atau API, ETL membantu untuk mengumpulkan dan mengintegrasikan data tersebut.
-
Membersihkan dan Memproses Data: Proses ETL memungkinkan kita untuk membersihkan, memanipulasi, atau mentransformasi data sehingga data tersebut siap digunakan untuk analisis lebih lanjut.
-
Memindahkan Data ke Tujuan yang Tepat: ETL memungkinkan kita untuk memindahkan data yang telah diolah ke tempat penyimpanan atau warehouse yang lebih cocok untuk analisis atau penggunaan lainnya.
Pada tutorial ini, kita akan menggunakan Python untuk melakukan proses ETL dari sebuah database ke Google Drive menggunakan dataset Sakila. Artikel ini akan memberikan langkah-langkah detail untuk mengekstrak data, membersihkan, mentransformasi, dan mengunggah hasilnya ke Google Drive.
Langkah 1: Instalasi Library dan Persiapan ENV
Pertama, kita akan menginstal library yang diperlukan menggunakan pip agar dapat menjalankan proses ETL dan mempersiapkan ENV.
# Install library yang diperlukan menggunakan pip pip install pandas sqlalchemy oauth2client
Di sini, kita menggunakan perintah pip install untuk menginstal library yang dibutuhkan, seperti pandas, sqlalchemy, dan oauth2client. Jika library ini belum terinstal, perintah ini akan memastikan bahwa kita memiliki semua alat yang diperlukan untuk menjalankan proses ETL.
Setelah itu, Anda dapat membuat file .env dan mengisi variabel ENV di dalamnya seperti di bawah ini:
# Buat file .env dan isi variabel lingkungan
#Jalankan perintah ini di terminal atau buat manual dengan teks editor:
#Catatan: Ganti nilai variabel dengan kredensial yang sesuai
MYSQL_USER=your_mysql_username
MYSQL_PASSWORD=your_mysql_password
Selanjutnya, Anda dapat melanjutkan dengan kode untuk mengimpor library yang diperlukan dalam Python setelah membuat file .env dan mengisi variabel lingkungan:
# Import library yang akan digunakan
import pandas as pd
from sqlalchemy import create_engine
import numpy as np
from oauth2client.service_account import ServiceAccountCredentials
from googleapiclient.discovery import build
from googleapiclient.http import MediaFileUpload
import io
from dotenv import load_dotenv
load_dotenv()
Pastikan Anda telah mengganti nilai variabel ENV dalam file .env dengan kredensial yang sesuai dengan ENV MySQL Anda.
Langkah 2: Membaca Data dari Database
Pada langkah ini, kita akan mengekstrak data dari database MySQL dengan menggunakan fungsi run_etl_with_sakila_data(). Fungsi ini akan melakukan proses ETL pada dataset Sakila, memanfaatkan koneksi ke database MySQL, dan mengambil data dari beberapa tabel dalam database Sakila.
# ... (Langkah 3: Membersihkan Data dengan Metode Statistik)
#Fungsi ETL dengan dataset Sakila dan data cleaning menggunakan metode statistik
def run_etl_with_sakila_data():
# Mendapatkan kredensial MySQL dari variabel lingkungan (env)
db_user = os.environ.get('MYSQL_USER')
db_password = os.environ.get('MYSQL_PASSWORD')
db_host = 'localhost'
db_name = 'sakila'
# Koneksi ke database Sakila di MySQL
db_connection_str = f'mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}'
db_connection = create_engine(db_connection_str)
# Baca tabel-tabel yang diperlukan dari database Sakila dengan alamat lengkap
query = """
SELECT p.payment_id, c.customer_id AS user_id, CONCAT(c.first_name, ' ', c.last_name) AS full_name,
a.address AS full_address, a.district, a.postal_code, p.payment_date, f.title AS film_title
FROM payment p
INNER JOIN customer c ON p.customer_id = c.customer_id
INNER JOIN address a ON c.address_id = a.address_id
INNER JOIN rental r ON p.rental_id = r.rental_id
INNER JOIN inventory i ON r.inventory_id = i.inventory_id
INNER JOIN film f ON i.film_id = f.film_id
"""
df = pd.read_sql(query, con=db_connection)
# Memanggil fungsi clean_data untuk membersihkan data pada setiap kolom
df = clean_data(df)
# Tampilkan informasi pembayaran pelanggan dengan detail film yang dibayar
print(df.head())
return df
- Fungsi run_etl_with_sakila_data() mengambil kredensial MySQL dari variabel lingkungan yang telah diatur pada file .env. Kemudian, fungsi ini membuat koneksi ke database Sakila di MySQL.
- Fungsi membaca tabel-tabel yang diperlukan dari database Sakila dengan menggunakan query SQL. Data yang diambil mencakup informasi pembayaran pelanggan dengan detail film yang dibayar dari tabel seperti payment, customer, address, rental, inventory, dan film.
- Setelah membaca data, fungsi melakukan pemanggilan terhadap fungsi clean_data() untuk membersihkan data pada setiap kolom yang telah diekstrak sebelumnya.
- Sebagai tambahan, fungsi menampilkan informasi dari DataFrame yang dihasilkan dengan menggunakan print(df.head()).
- Akhirnya, fungsi mengembalikan DataFrame yang telah dimodifikasi dan siap untuk digunakan dalam proses ETL berikutnya.
Dengan menggunakan fungsi ini, Anda dapat mengekstrak data dari database Sakila dengan menggunakan Python dan melakukan berbagai transformasi dan pembersihan data yang diperlukan sebelum data digunakan untuk analisis lebih lanjut.
Langkah 3: Membersihkan Data dengan Metode Statistik
Pada langkah ini, kita menggunakan fungsi clean_data() untuk membersihkan data yang telah diekstrak dari database. Proses ini melibatkan penanganan nilai yang hilang (missing values) dan pengisian nilai-nilai tersebut menggunakan metode statistik seperti mean (rata-rata), median, dan mode. Fungsi ini memastikan data yang diperoleh sudah siap digunakan tanpa mengorbankan integritas informasi.
# Fungsi untuk membersihkan data pada kolom numerik dan kategorikal
def clean_data(df):
# Menghitung proporsi missing value pada setiap kolom
missing_prop = df.isnull().mean()
# Menghapus baris jika proporsi missing value dibawah 10%
rows_to_drop = missing_prop[missing_prop < 0.10].index.tolist()
df = df.dropna(subset=rows_to_drop)
# Kolom-kolom numerik: Mengisi nilai null dengan mean jika terdistribusi normal, dan median jika tidak
numeric_cols = df.select_dtypes(include=np.number).columns.tolist()
for col in numeric_cols:
if df[col].isnull().sum() > 0:
if df[col].dtype != 'object':
if df[col].skew() > 1 or df[col].skew() < -1: # Jika distribusi tidak normal (skewness > 1 atau < -1)
df[col] = df[col].fillna(df[col].median())
else: # Jika terdistribusi normal
df[col] = df[col].fillna(df[col].mean())
# Kolom-kolom kategorikal: Mengisi nilai null dengan mode
categorical_cols = df.select_dtypes(include='object').columns.tolist()
for col in categorical_cols:
if df[col].isnull().sum() > 0:
df[col] = df[col].fillna(df[col].mode()[0])
return df
#...(Langkah 2: Membaca Data dari Database)
- Fungsi clean_data() pertama-tama menghitung proporsi missing values pada setiap kolom dengan menggunakan df.isnull().mean(). Ini membantu kita memahami seberapa banyak nilai yang hilang pada setiap kolom.
- Kemudian, fungsi menghapus baris-baris yang memiliki proporsi missing values di bawah 10%. Jika proporsi missing values lebih kecil dari 10%, baris-baris tersebut dihapus dari dataset.
- Selanjutnya, fungsi menangani nilai-nilai yang hilang pada kolom numerik. Jika kolom numerik memiliki nilai null, fungsi akan mengisi nilai tersebut dengan rata-rata (mean) jika kolom memiliki distribusi normal, atau dengan median jika distribusi kolom tidak normal (dilihat dari skewness).
- Terakhir, fungsi menangani nilai-nilai yang hilang pada kolom kategorikal. Jika kolom kategorikal memiliki nilai null, fungsi akan mengisi nilai tersebut dengan nilai mode. Dengan menggunakan metode statistik ini, kita memastikan data yang telah diekstrak dan bersih dari missing values sehingga siap digunakan untuk proses analisis dan pemodelan data.
Langkah 4: Upload Data yang Telah Diolah ke Google Drive
Pada langkah ini, kita akan mengunggah data yang telah dibersihkan dan disimpan dalam format file CSV ke Google Drive menggunakan Google Sheets API.
Cara mendapatkan FOLDER_ID untuk target folder yang ingin diupload Untuk mendapatkan FOLDER_ID dari folder yang sudah ada di Google Drive, Anda dapat mengikuti langkah-langkah berikut:
-
Buka Google Drive di browser Anda dan navigasi ke folder yang ingin Anda gunakan untuk menyimpan file yang diunggah dari aplikasi Anda.
-
Di URL di atas (address bar) pada browser Anda, Anda akan melihat serangkaian karakter yang unik setelah /folders/ atau /drive/folders/. Itulah FOLDER_ID dari folder yang sedang Anda lihat.
Sebagai contoh, jika URL-nya adalah https://drive.google.com/drive/folders/abc123xyz456, maka FOLDER_ID-nya adalah abc123xyz456.
Setelah mendapatkan FOLDER_ID, Anda dapat menyisipkannya ke dalam file .env sebagai variabel lingkungan (environment variable). Misalnya, Anda dapat menambahkan baris berikut ke dalam file .env:
# Buat file .env dan isi variabel lingkungan
#Jalankan perintah ini di terminal atau buat manual dengan teks editor:
#Catatan: Ganti nilai variabel dengan kredensial yang sesuai
MYSQL_USER=your_mysql_username
MYSQL_PASSWORD=your_mysql_password
FOLDER_ID=abc123xyz456
Pastikan untuk menyimpan file .env setelah menyisipkan FOLDER_ID. Dengan cara ini, Anda bisa menggunakan variabel lingkungan ini dalam aplikasi Anda tanpa perlu membuat folder baru secara manual melalui kode.
Cara mendapatkan file Kredensial (credentials.json) untuk Google Drive API:
Buka Google Cloud Console:
- Masuk ke Google Cloud Console dengan akun Google Anda.
Aktifkan API dan Layanan yang Diperlukan:
-
Klik pada menu hamburger (garis tiga horizontal) di bagian kiri atas halaman.
-
Pilih “API & Services” > “Library”.
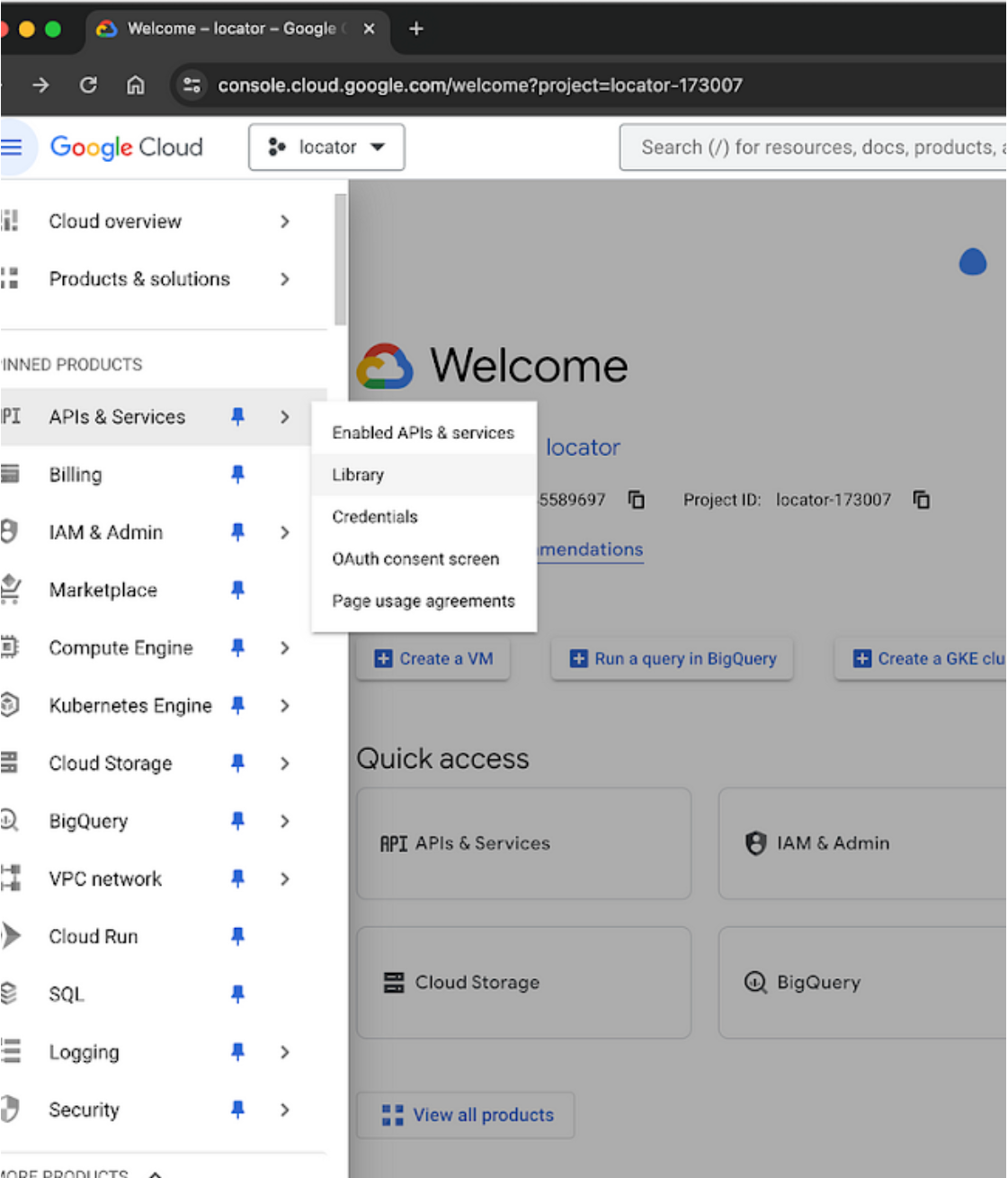
- Di dalam “Library”, Anda dapat mencari dan aktifkan “Google Drive API” dan “Google Sheets API”.
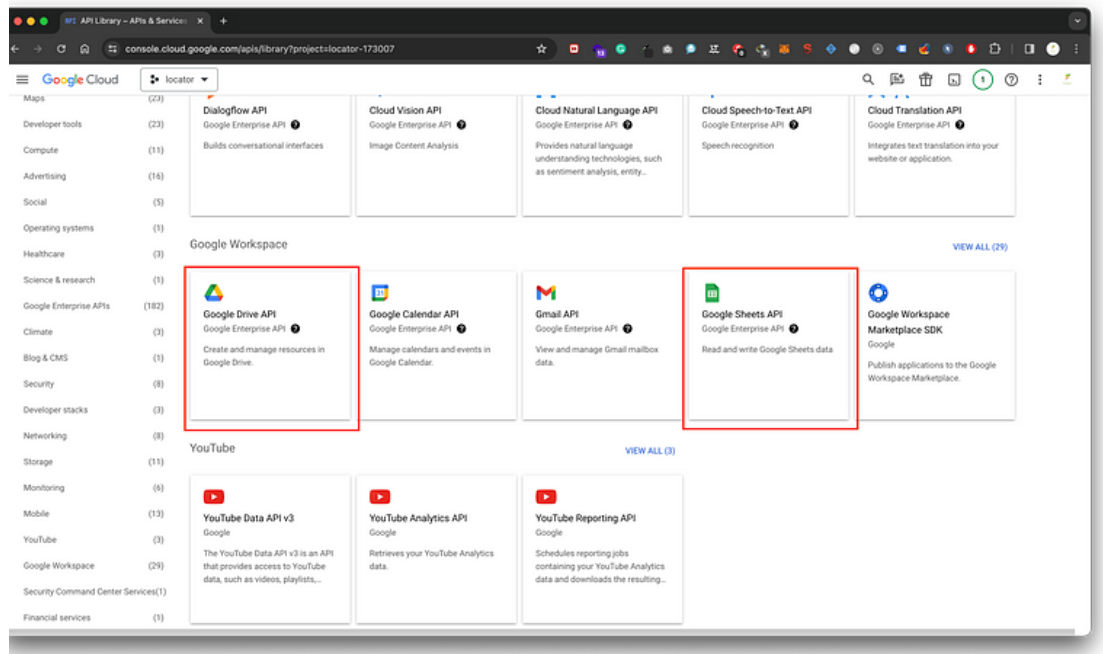

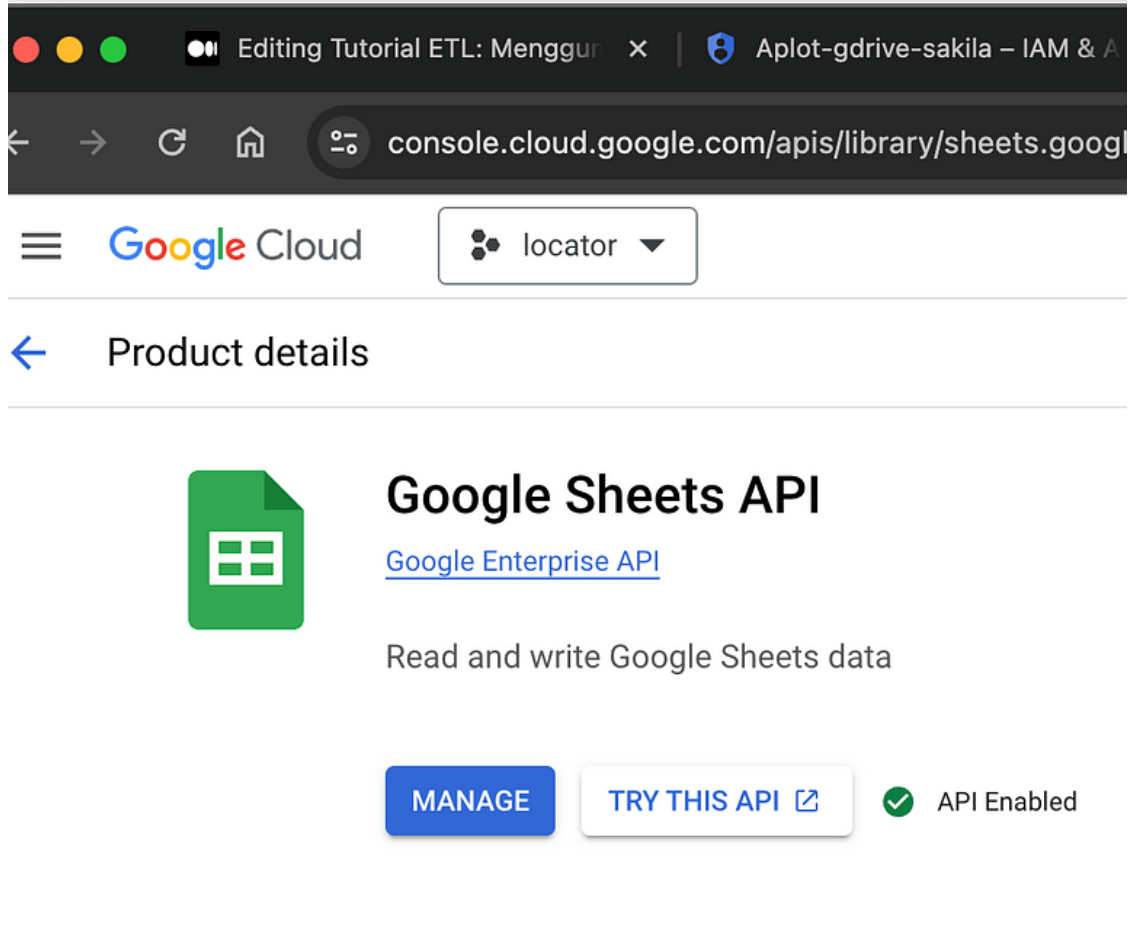
Buat Kredensial API (Service Account):
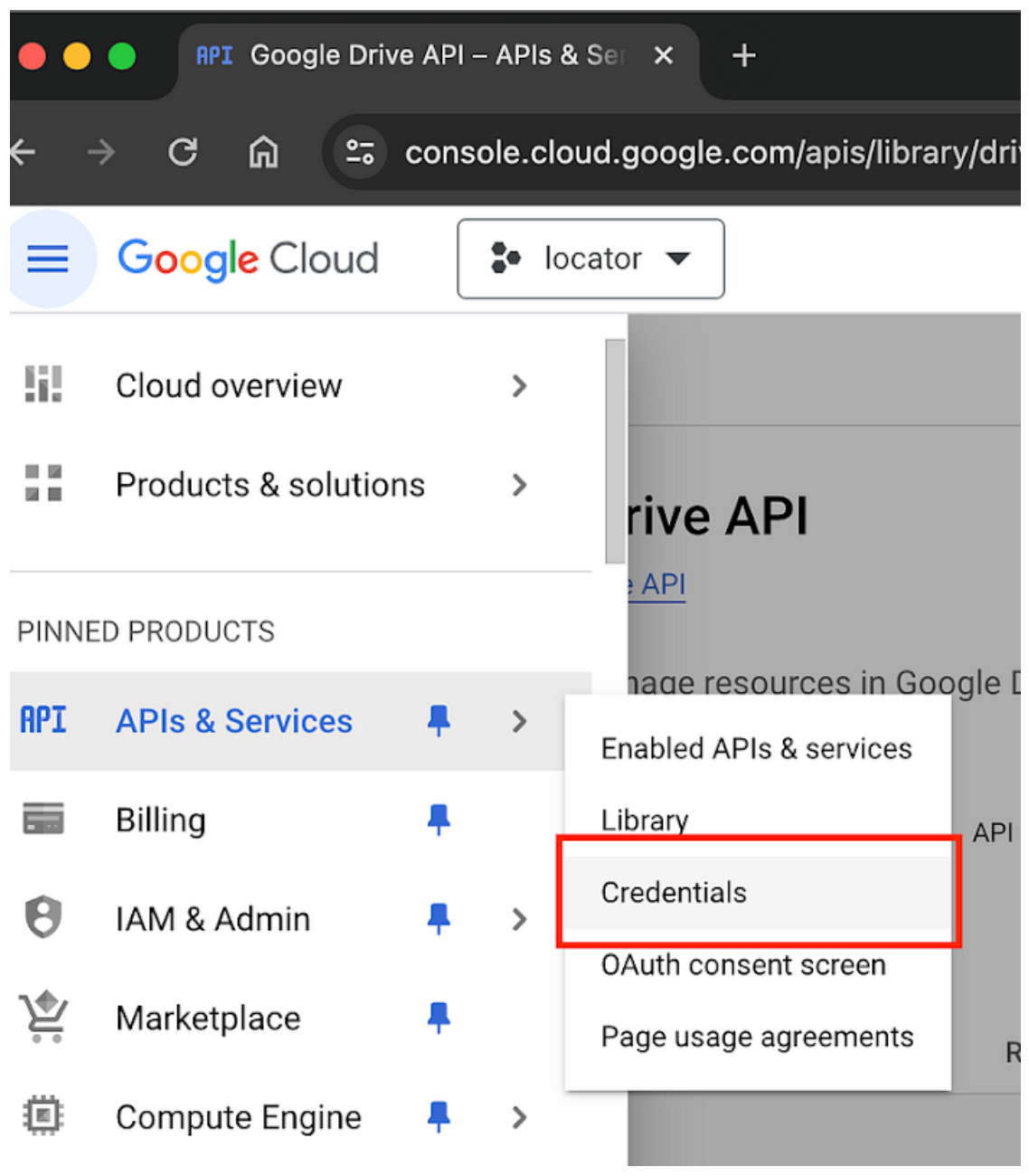
· Di panel navigasi, pilih “Credentials” di bawah “APIs & Services”.
· Klik “Create credentials” lalu pilih “Service account”.
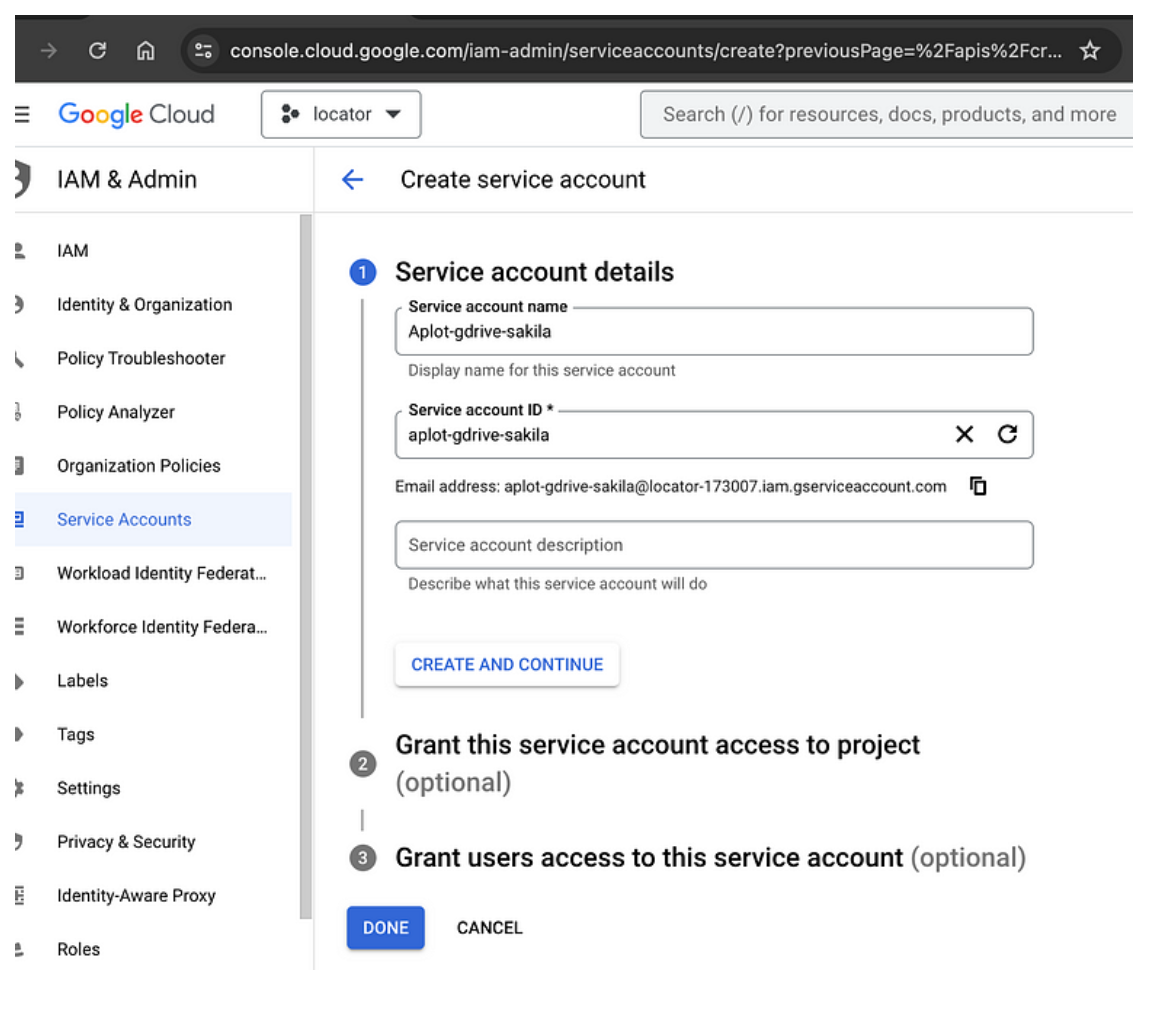
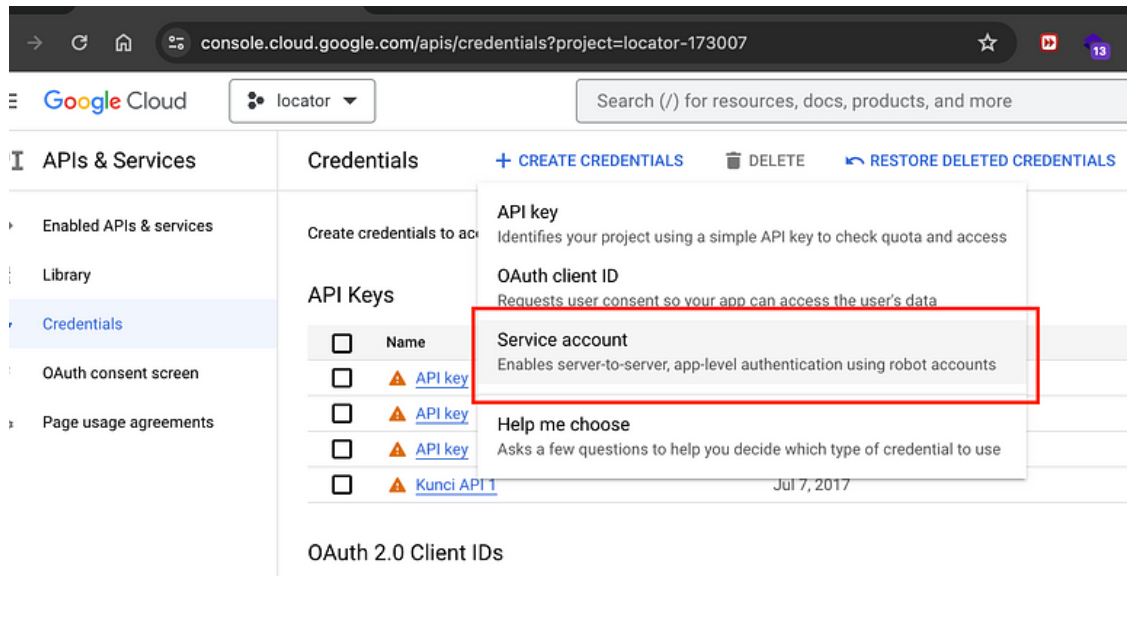 · Isi detail untuk service account baru Anda, termasuk nama dan akses ke Google Drive.
· Isi detail untuk service account baru Anda, termasuk nama dan akses ke Google Drive.
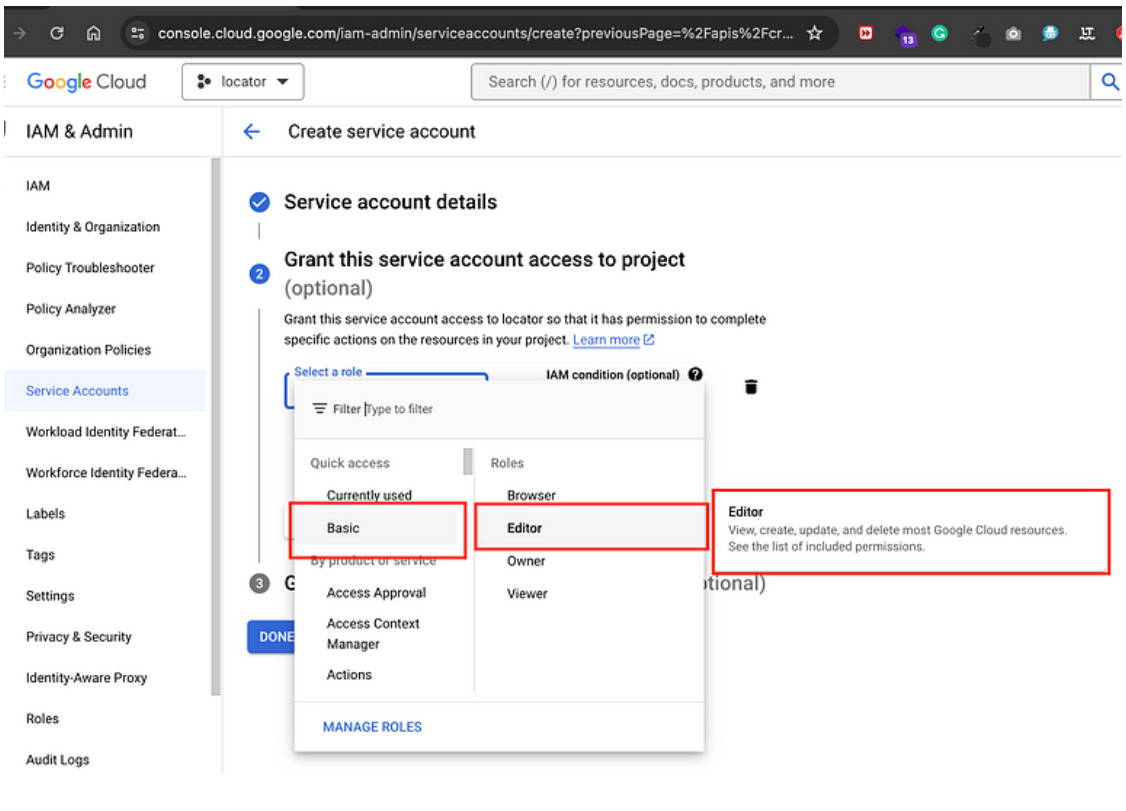
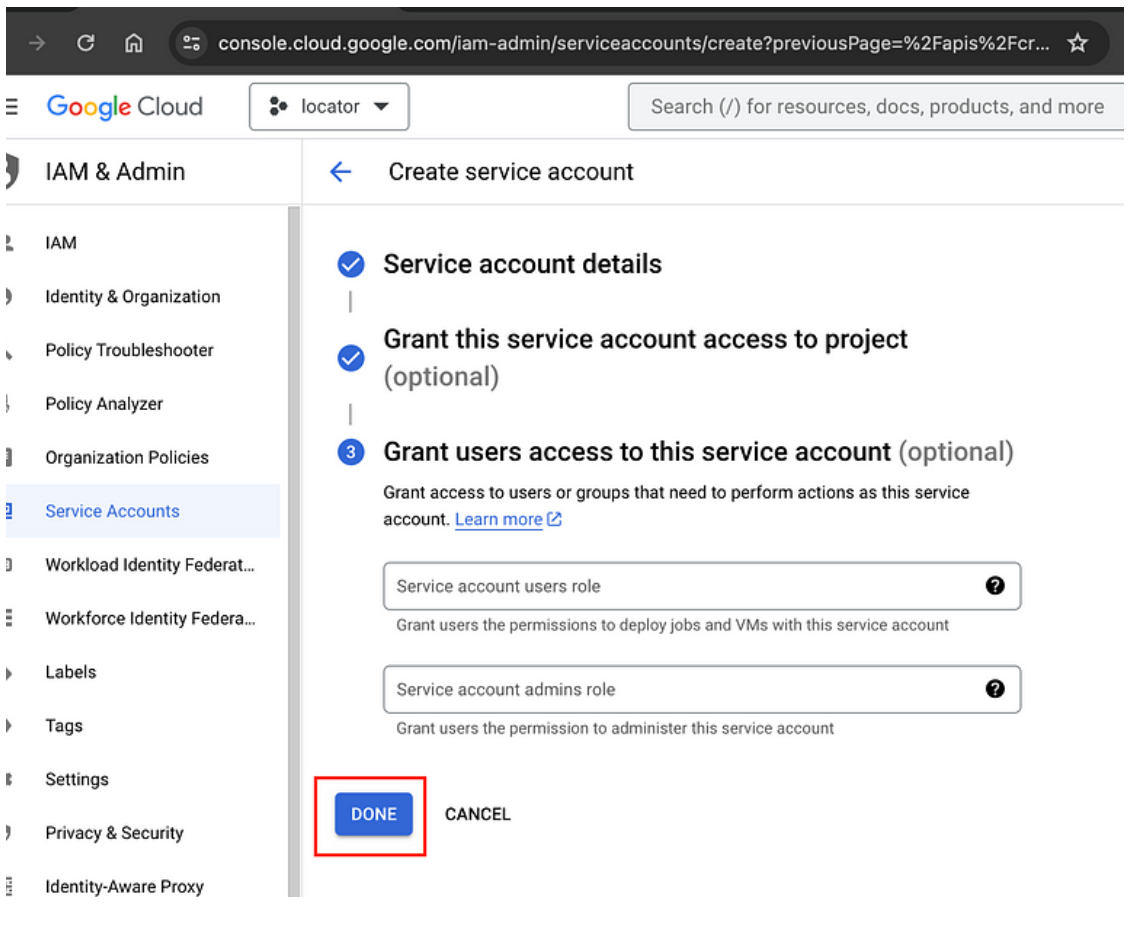
· Setelah membuat service account, klik “Done”.
Unduh File Kredensial JSON (credentials.json):
· Di daftar credentials, temukan service account yang baru saja Anda buat.
· Klik pada tiga titik di sebelah nama service account dan pilih “Manage keys”.
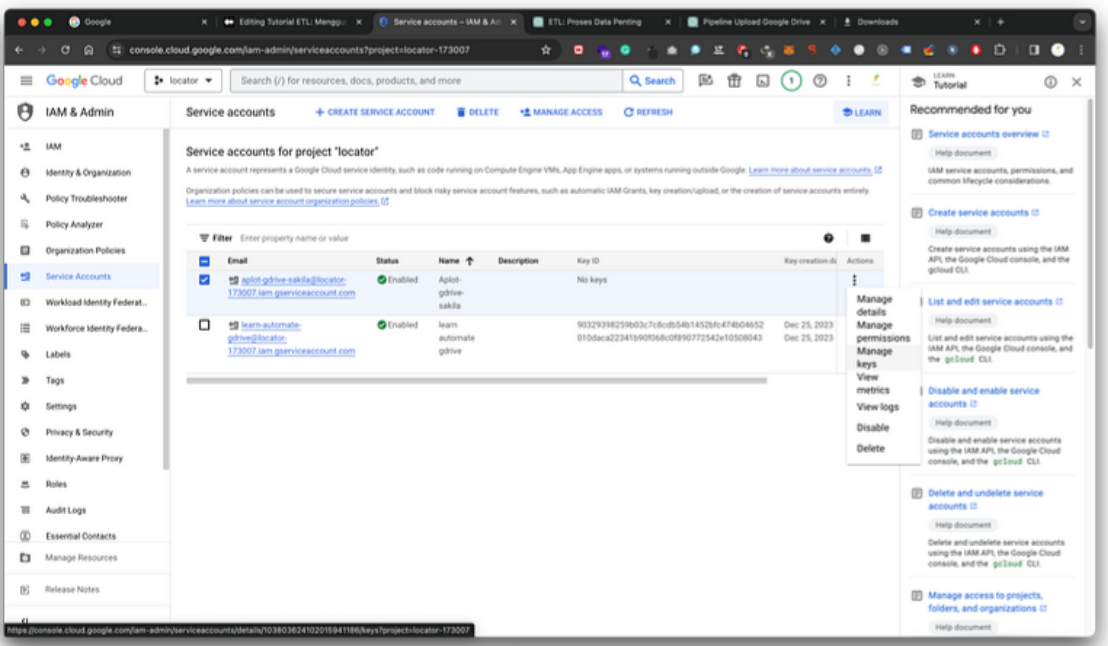
· Klik “Add key” lalu pilih “Create new key
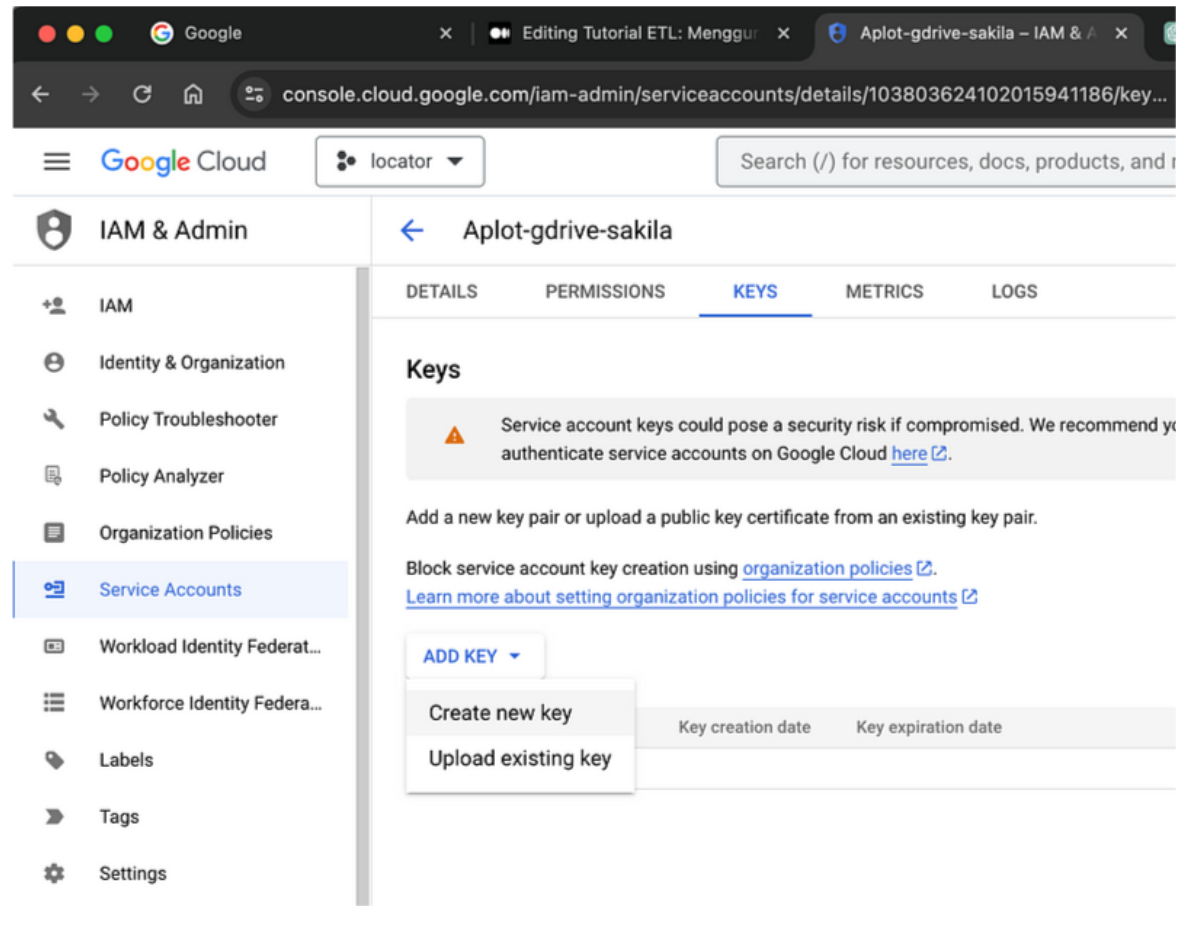
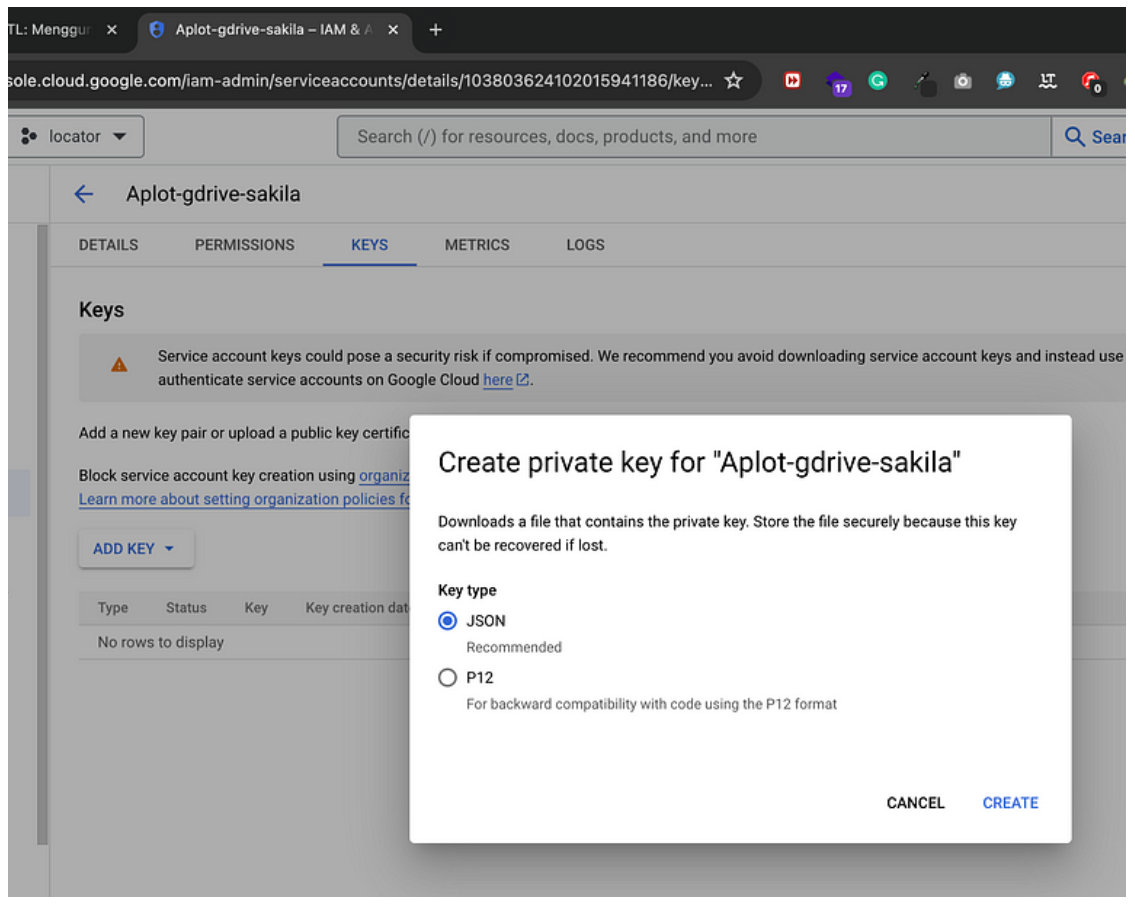
· Pilih tipe key sebagai JSON dan klik “Create”.
· File JSON yang berisi kredensial akan diunduh ke komputer Anda. Pastikan untuk menyimpannya dengan aman.
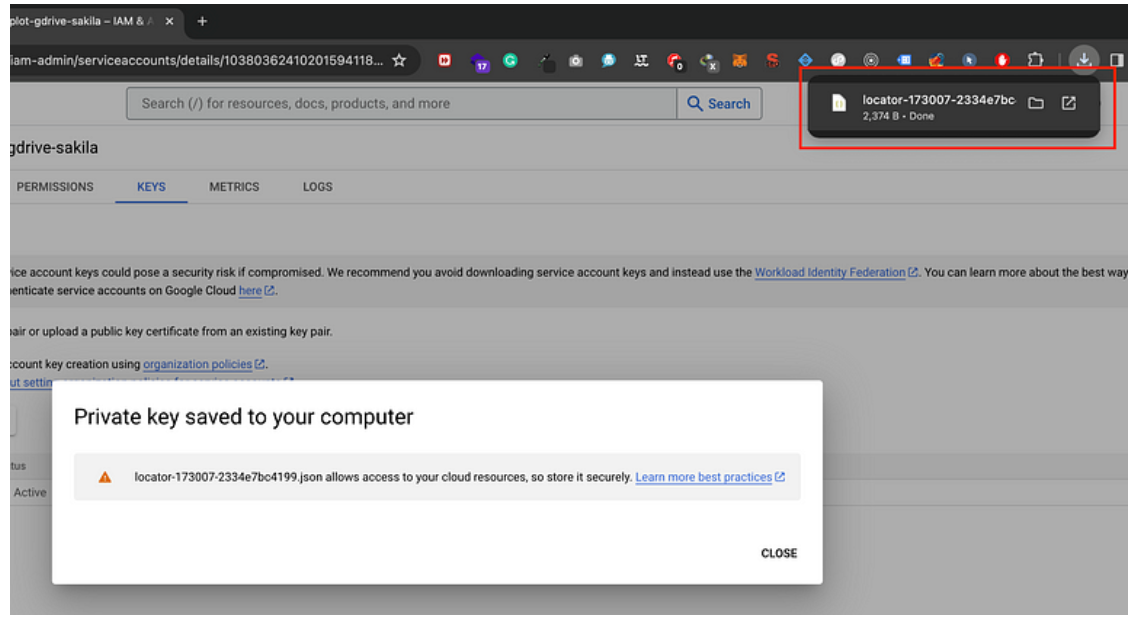
Upload Data ke Google Drive dengan Kredensial yang Didapatkan: Setelah Anda mendapatkan file JSON kredensial (credentials.json), Anda dapat menggunakannya untuk otentikasi ke Google Drive API pada skrip Python Anda. Pastikan untuk menyimpan file tersebut di lokasi yang aman dan hanya digunakan pada proyek yang sesuai.
Berikut adalah potongan kode yang menggunakan file kredensial tersebut dalam fungsi upload_dataframe_to_google_drive() untuk mengunggah data ke Google Drive:
# Fungsi untuk autentikasi ke Google Drive dan unggah data dari pandas DataFrame
def upload_dataframe_to_google_drive(df, file_name):
scope = ['https://www.googleapis.com/auth/drive']
# Menggunakan file kredensial JSON untuk otentikasi ke Google Drive API
credentials = ServiceAccountCredentials.from_json_keyfile_name('credentials.json', scope)
drive_service = build('drive', 'v3', credentials=credentials)
# Konversi DataFrame ke CSV (dalam hal ini, df adalah DataFrame yang ingin Anda unggah)
csv_data = df.to_csv(index=False)
with open(file_name, 'w') as f:
f.write(csv_data)
# Set metadata untuk file yang akan diunggah
file_metadata = {
'name': file_name,
'parents': [os.environ.get('FOLDER_ID')] # ID folder tujuan di sini
}
media = MediaFileUpload(file_name, mimetype='text/csv')
# Lakukan unggah file ke Google Drive
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print('File ID:', file.get('id'))
# Hapus file lokal setelah diunggah
os.remove(file_name)
-
scope = ['https://www.googleapis.com/auth/drive']: Variabel scope menentukan lingkup akses yang diminta saat mengakses Google Drive API. Di sini, kita hanya meminta akses ke layanan Drive.
-
credentials = ServiceAccountCredentials.from_json_keyfile_name('credentials.json', scope): Membaca file kredensial JSON (credentials.json) dan membuat objek kredensial dari file tersebut untuk mengautentikasi aplikasi ke API Google Drive.
-
drive_service = build('drive', 'v3', credentials=credentials): Membuat objek layanan Google Drive API yang akan digunakan untuk berinteraksi dengan Drive.
-
csv_data = df.to_csv(index=False): Mengonversi DataFrame (df) menjadi data CSV.
-
with open(file_name, 'w') as f: f.write(csv_data): Membuka file dengan nama yang diberikan (file_name) dan menuliskan data CSV ke dalamnya.
-
file_metadata: Mengatur metadata untuk file yang akan diunggah, termasuk nama file dan ID folder tujuan di Google Drive.
-
media = MediaFileUpload(file_name, mimetype='text/csv'): Membuat objek MediaFileUpload untuk mengunggah file.
-
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute(): Melakukan proses unggah file ke Google Drive dengan metadata dan kontennya.
-
print('File ID:', file.get('id')): Mencetak ID file yang baru saja diunggah.
-
os.remove(file_name): Menghapus file lokal setelah proses unggah selesai.
Dengan menggunakan fungsi ini, Anda dapat mengunggah data yang telah diolah dari DataFrame ke Google Drive dan menyimpannya dalam bentuk Google Sheets untuk berbagai keperluan seperti analisis lanjutan, visualisasi, atau berbagi data dengan tim Anda.
Langkah 5: Menyimpan Data yang Telah Dibersihkan dan Mengunggah ke Google Drive
Pada langkah ini, kita akan melakukan penyimpanan data yang telah dibersihkan ke dalam file CSV dan mengunggahnya ke Google Drive.
# Jalankan proses ETL dengan data cleaning pada dataset Sakila untuk informasi pembayaran
df = run_etl_with_sakila_data()
#Simpan data ke file CSV baru setelah cleaning new_file_name = 'sakila_payment_details_cleaned.csv' df.to_csv(new_file_name, index=False)
#Unggah data dari DataFrame yang telah diolah ke Google Drive upload_dataframe_to_google_drive(df, file_name=new_file_name)
Eksekusi Proses ETL dengan Data Cleaning pada Dataset Sakila:
-
Langkah ini menjalankan fungsi run_etl_with_sakila_data() yang melakukan proses Ekstraksi, Transformasi, dan Load (ETL) pada dataset Sakila.
-
Data dari database diekstrak, dibersihkan, dan disiapkan dalam DataFrame df untuk analisis lebih lanjut.
Simpan Data ke File CSV Baru Setelah Pemrosesan Bersih (Cleaning):
-
Data yang telah dibersihkan dan dimodifikasi disimpan ke dalam file CSV baru dengan nama ‘sakila_payment_details_cleaned.csv’.
-
Langkah ini memanfaatkan fungsi to_csv() dari pandas untuk menyimpan data dari DataFrame ke dalam format CSV tanpa menyertakan indeks.
Unggah Data dari DataFrame yang Telah Diolah ke Google Drive:
- Setelah data dibersihkan dan disimpan dalam file CSV, langkah ini menggunakan fungsi upload_dataframe_to_google_drive() untuk mengunggah data dari DataFrame langsung ke Google Drive.
Dengan rangkaian langkah ini, data dari dataset Sakila telah diproses, dibersihkan, disimpan dalam file CSV, dan diunggah ke Google Drive, siap untuk digunakan dalam berbagai analisis atau untuk berbagi dan berkolaborasi dengan tim Anda.
Kesimpulan
Dalam tutorial ini, kita telah menjalankan proses ETL untuk membersihkan, mentransformasi, dan mengunggah data dari database MySQL ke Google Drive menggunakan Python. Dengan mengikuti langkah-langkah ini, Anda akan dapat memahami proses ETL dan menerapkannya pada proyek Anda sendiri. Jika Anda ingin melihat contoh implementasi dari tutorial ini, silakan kunjungi repositori GitHub saya di bawah ini.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara