


Revolutionizing Data Science: Dask's Journey to Scalable Computing
Budiman Akbar Radhiansyah
∙23 February 2024

In the rapidly evolving landscape of data science, the insurmountable growth in data volume and complexity demands transformative tools that can efficiently handle large-scale computations. Enter Dask: a parallel computing library meticulously designed to seamlessly scale and empower a diverse array of Python libraries, including NumPy, Pandas, Scikit-learn, and others. This essay delves into the pivotal role of Dask in revolutionizing data science workflows, leveraging excerpts from an enlightening video to highlight its capabilities and far-reaching implications.
Dask, with its ability to parallelize computations across multiple cores and distributed clusters, addresses the limitations of traditional Python libraries that struggle with large datasets or memory constraints. Its seamless integration with existing Python ecosystems, as elaborated in the video, heralds a significant breakthrough. By replacing NumPy with Dask array, a seamless transition to parallel computing is enabled, allowing scalable execution on multi-core machines or expansive distributed clusters.
One of the pivotal aspects emphasized in the video is how Dask facilitates this transition without necessitating a steep learning curve or significant code rewrites. Its compatibility with various Python environments, including Jupyter notebooks and automated scripts, highlights its flexibility and ease of integration. The incorporation of cloud data sources and support for common deployment systems like Kubernetes or HDFS further amplifies its versatility and applicability in diverse computing environments.
A compelling feature outlined in the video is the user-friendly visibility into distributed computations offered by Dask. Through intuitive and interactive dashboards, data scientists gain insight into the computation process, fostering a deeper understanding of complex operations. This transparency empowers users to comprehend and optimize their computations effectively, without requiring specialized expertise in distributed systems.
Moreover, the adaptability of Dask to a multitude of data science domains, showcased through examples like Dask DataFrame for tabular computing and Dask array for multidimensional analysis in fields like biomedical research, geosciences, and simulations, underscores its versatility and broad applicability.
The seamless integration of Dask with core libraries like NumPy, Pandas, and Scikit-learn is pivotal. This integration, both in terms of user API and community collaboration, ensures a unified experience and fosters cohesion among projects while enhancing scalability.
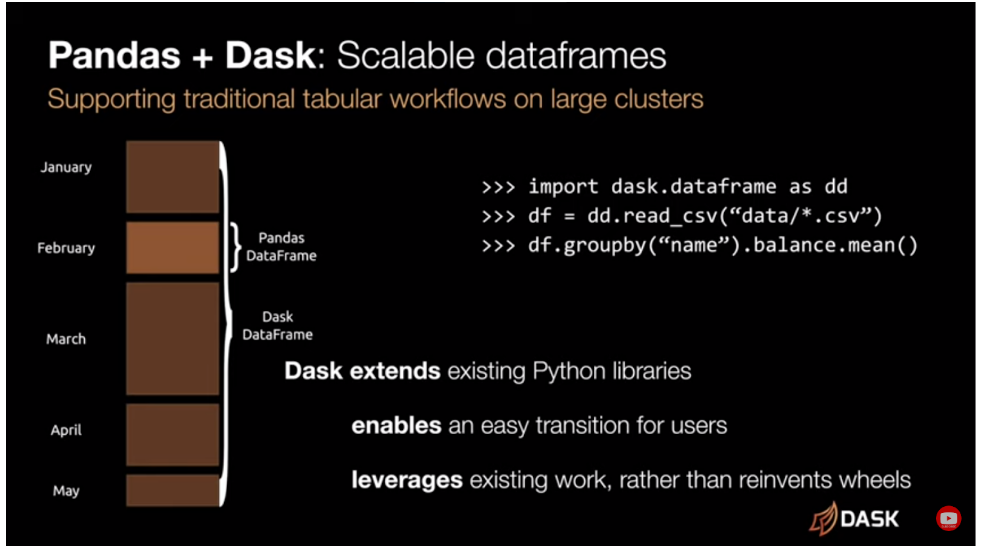
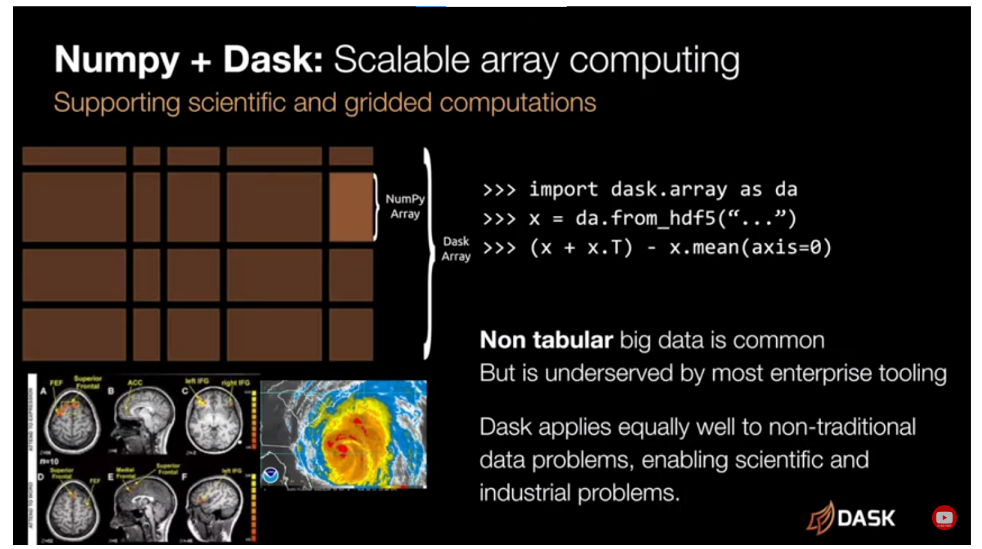
Dask's flexible architecture finds applications not just in traditional big data domains but also in novel fields, as mentioned in the video. Its integration into projects like X-Array, Prefect, NVIDIA Rapids, and customized computations in research or finance, speaks volumes about its adaptability and efficacy in diverse contexts.
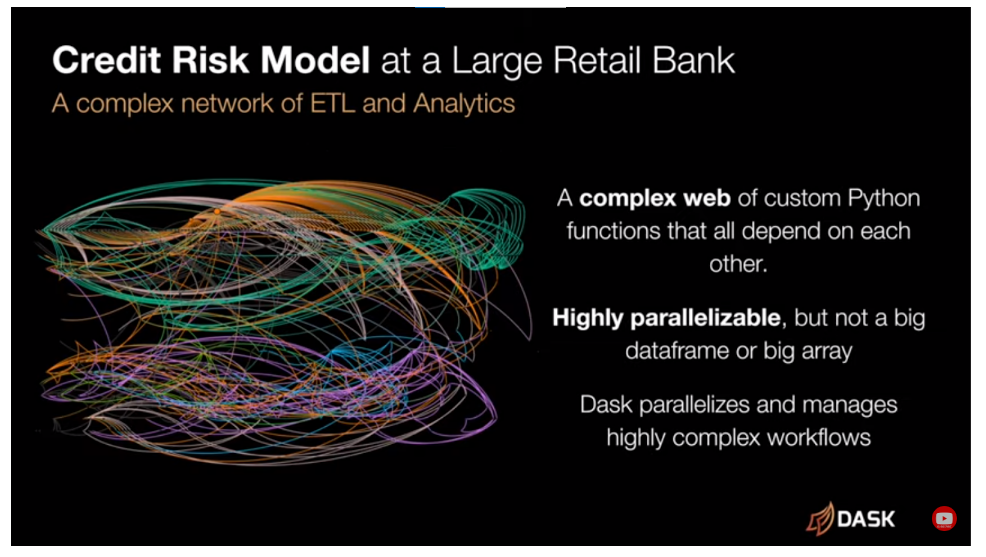
From a technical perspective, Dask's distributed service architecture enables centralized management, distributed execution, and storage, providing a hassle-free deployment across various resource managers and cloud environments. Its ease of installation and deployment on local machines to institutional hardware further cements its accessibility and user-friendliness.
In conclusion, Dask stands as a pinnacle of innovation, bridging the gap between traditional Python libraries and scalable distributed computing. Its transformative capabilities not only streamline large-scale data analysis but also empower users across a spectrum of domains to harness the potential of distributed hardware seamlessly. As an integral part of the vibrant open-source Python ecosystem, Dask symbolizes the collaborative spirit driving modern data science, promising a future of scalable and efficient computation for all.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara