


Proving Real Madrid's Dominance with Web Scraping: A Data-Driven Analysis
Hizkia Simaremare
∙26 November 2024

Are you tired of endless debates about which club is more successful in Spain: Real Madrid or Barcelona? It's time to put the arguments to rest using the power of web scraping! In this article, we'll show you how to extract and analyze data from Wikipedia to definitively prove Real Madrid’s dominance in Spanish football.
The Power of Web Scraping in Data Analysis
In today's data-driven world, the ability to extract valuable information from the vast expanse of the internet is a game-changer. Web scraping, the process of extracting data from websites, has become an essential tool for data analysts and researchers. By leveraging web scraping, you can gather and analyze data to uncover insights, make informed decisions, and even drive business strategies.
What is Web Scraping?
Web scraping is a technique used to collect large amounts of data from websites. This data, which is often publicly available, can be processed and analyzed to gain insights, make decisions, and even drive business strategies. From gathering information on job listings to tracking product prices, web scraping opens a world of possibilities.
However, it's important to note that not all data on the internet is meant to be freely accessed or used. Some websites have terms of service that restrict or forbid scraping, and some data may be sensitive or protected by privacy laws. Therefore, it’s crucial to understand and respect the legality and ethics of web scraping. Always check the website's ‘robots.txt’ file and terms of service for scraping permissions and, when necessary, request permission to scrape data. By being mindful of these considerations, you can responsibly use web scraping in your data analysis projects.
Why Web Scraping is Ideal for Sports Analytics
One of the key strengths of web scraping is its ability to handle large datasets efficiently. Sports analytics often requires analyzing extensive historical data to identify patterns, trends, and insights. Web scraping makes it possible to collect this data from various sources, such as sports news websites, official league sites, and fan forums, ensuring a comprehensive dataset.
In the realm of football, historical data on matches, player statistics, and club achievements is crucial for any meaningful analysis. Web scraping allows us to gather this information in a structured format, enabling detailed analysis and visualization. Today, we’re applying web scraping to the world of football to demonstrate its power and versatility.
Steps Involved in Web Scraping for Data Analysis
1. Identify the Target Website
First, we need to identify the website we want to scrape. In this case, we’ll use Wikipedia to gather historical data on the Spanish Football League, focusing on the achievements of Real Madrid and Barcelona.
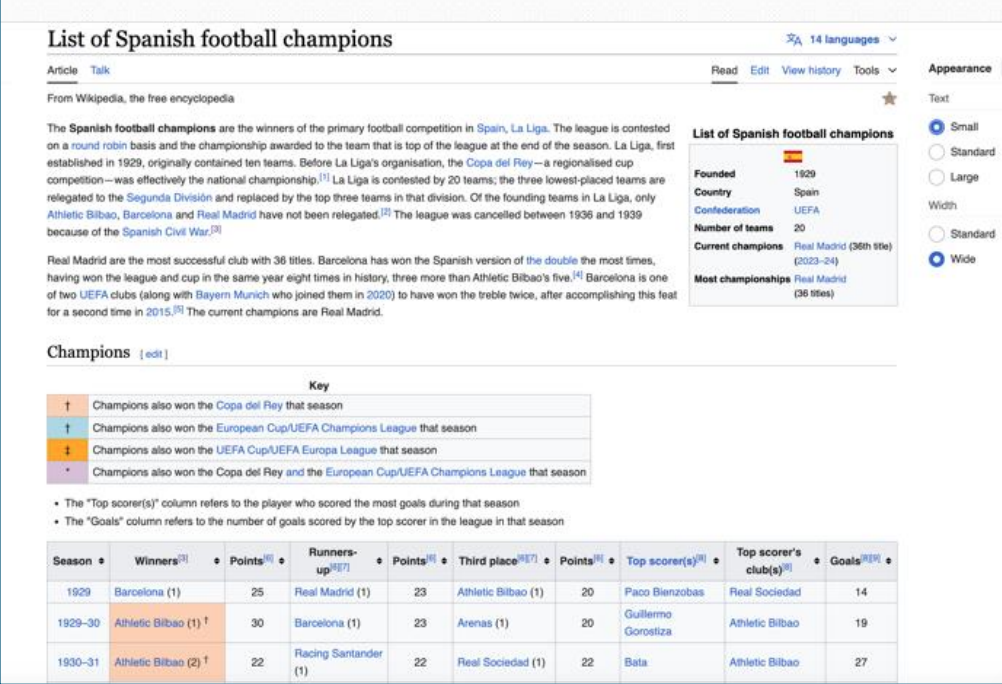
2. . Inspect the Web Page
Using browser tools like Chrome DevTools, we’ll inspect the structure of the web page. We’re looking for HTML tags and classes that contain data about seasons, club names, achievements, points, top scorers, and other relevant information.
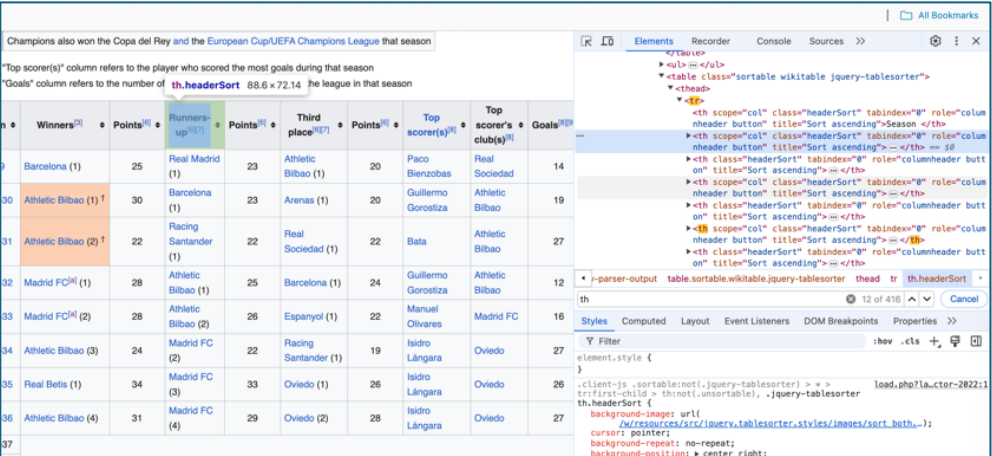
3. Choose a Web Scraping Tool & Write the Scraping Code
We’ll start by importing the necessary libraries and writing a script to fetch the web page and extract the required data. For this example, we’ll use BeautifulSoup, a popular Python library for parsing HTML and XML documents. Other tools you could consider include Scrapy and Selenium for more complex scraping needs.
Here is the full scraping code to get the Spanish Football League information:

4. Handle Pagination
If the data spans multiple pages, handle pagination by iterating through each page and extracting data. This ensures a comprehensive dataset. However, in this example we don’t need to handle pagination because all the data we need are placed in a single Wikipedia page.
5. Data Cleaning
Clean the scraped data to remove duplicates, handle missing values, and format it appropriately for analysis. For example, you might find that Real Madrid was once known as Madrid FC. Standardize these names for consistency.
Now let’s begin with checking on each column in the data and all the missing values in each column.
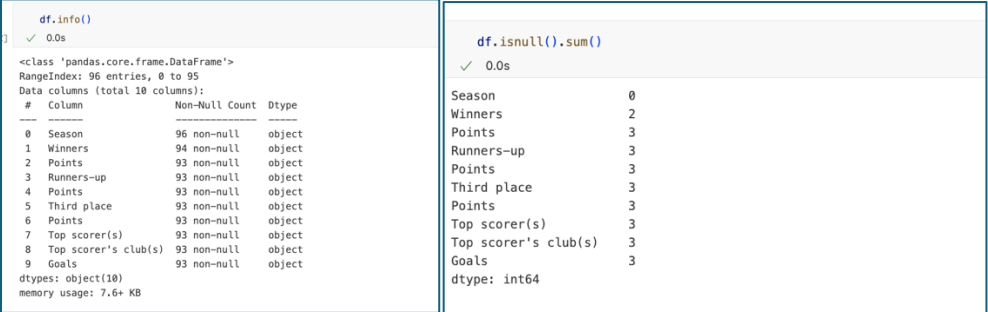
Here we can see there are 10 columns and 96 data /entries with total of 2-3 missing values in some columns.
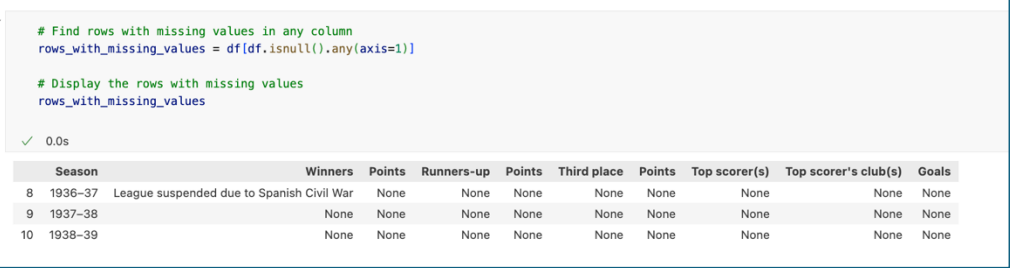
Missing values happens in data within year of 1936-1939. We can see there is no record /data because the league was suspended due to Spanish Civil War, therefore we will drop those datas.
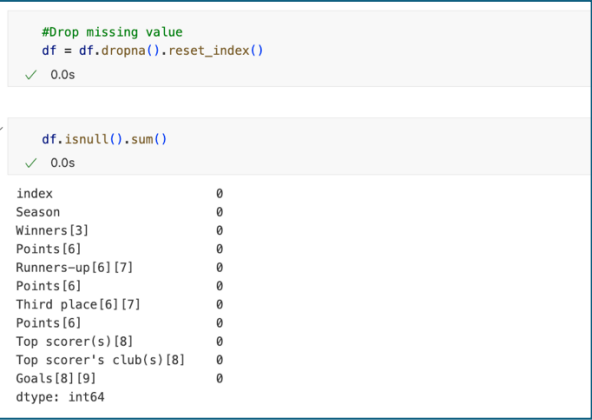
After we drop the missing values, we want to double check before continues by using .isnull() function. As we can see number missing values is zero.
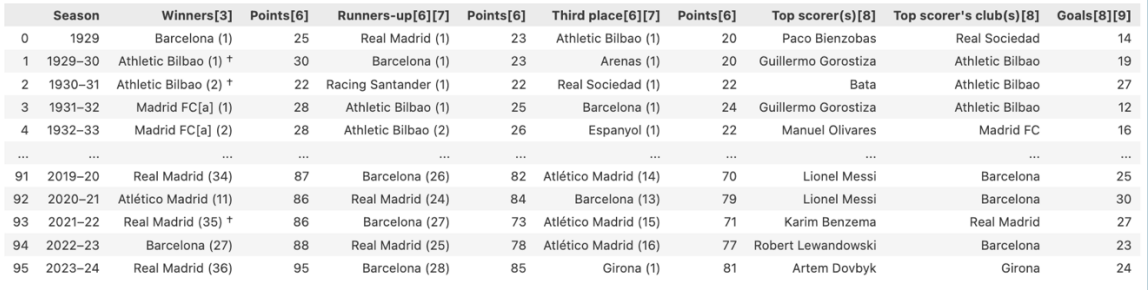
In data frame below we see that there are few things we need to fix:
-
Clean columns and clubs name from special character for example “Winners[3]”, "Athletic Bilbao (1) †" , "Barcelona (26)" etc.
-
There are two clubs changed its name; Real Madrid were known as Madrid FC from 1931 until 1941and Atlético Madrid were known as Atlético Aviación from 1939 until 1947. We want to change the previous name into current name.
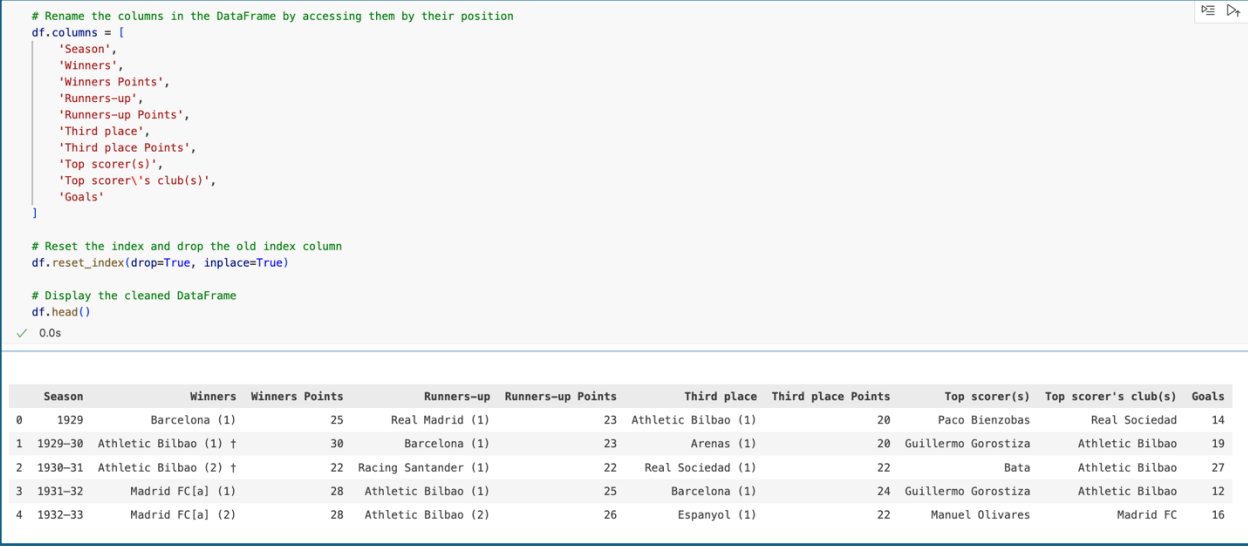
Here’s how we do it:
Let’s start with rename the head of columns.
Then we remove any special characters from club’s name.
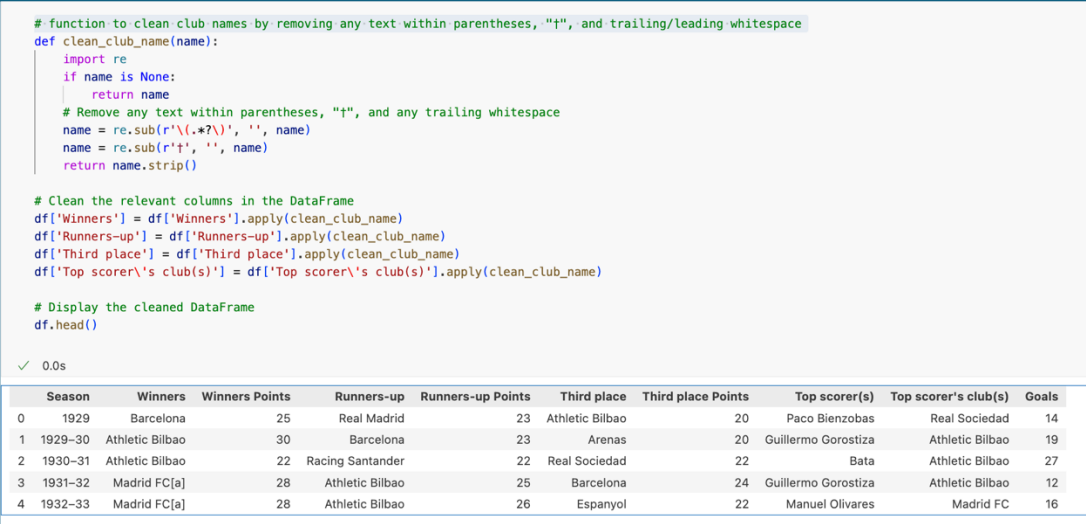
After we remove special character, now we let’s check which column Real Madrid and Atletico Madrid still using their old name in.
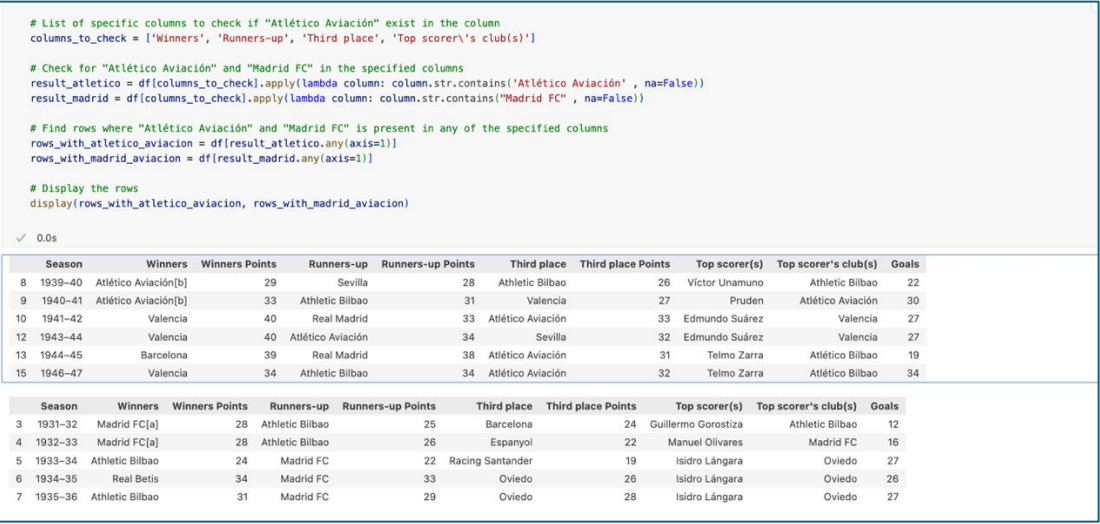
Then we rename the old names (including names with “[a]” & “[b]”) with new names.

Lastly let’s double check everything. Here we check whether “Madrid FC” and “Atlético Aviación” still exist in DataFrame. As we can see, there is none of them exist.
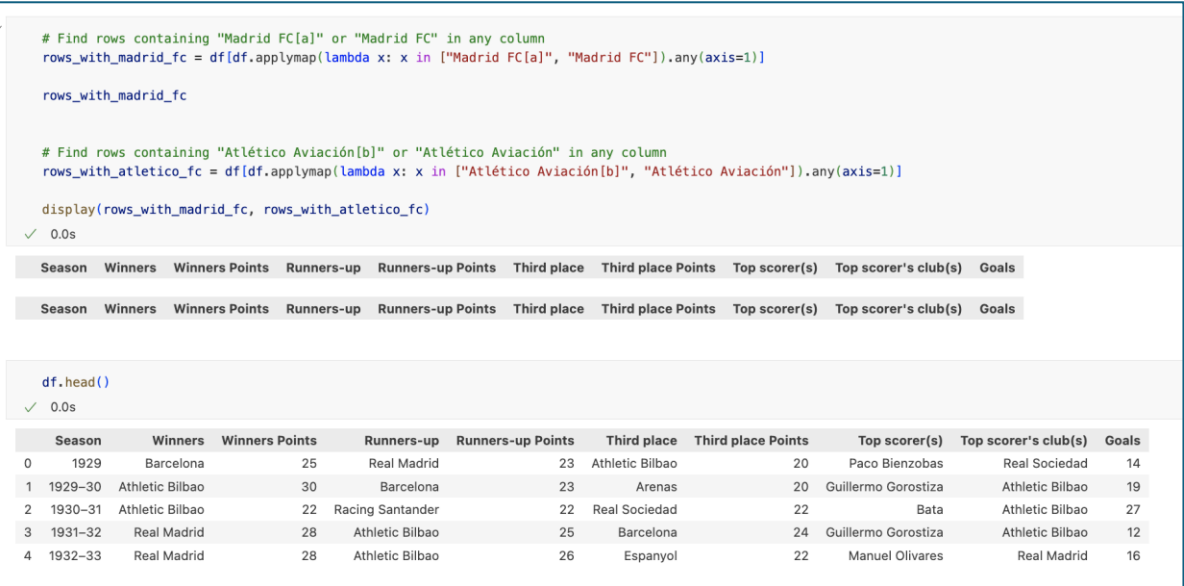
After making sure “Madrid FC” and “Atlético Aviación” don’t exist in DataFrame anymore, we need to change the datatype of “Season” from object type into date type.
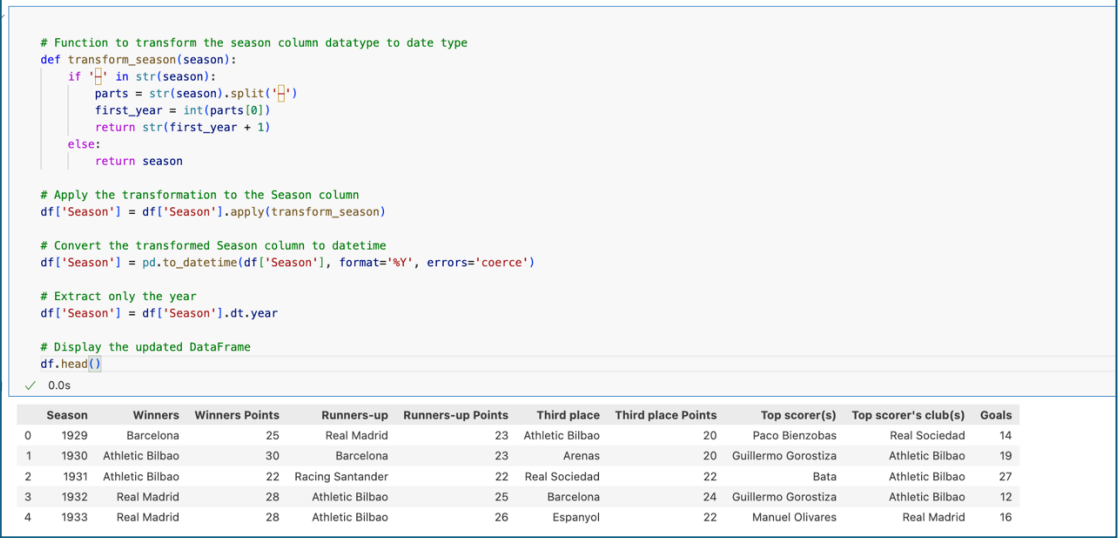
Now, the data is ready to use.
6. Store the Data
As the data ready to use, we can store the data in a structured format such as CSV. This makes it easier to analyze and visualize later.

7. Analyze the Data
Use data analysis tools and libraries like Pandas, NumPy, and Matplotlib in Python to analyze and visualize the data. Here’s how you can analyze the number of titles won by each club:
Here is an example how data scrapped from internet can be used. This is only simple example of the process of data scrapping up to the usage or optimization of extracted data.
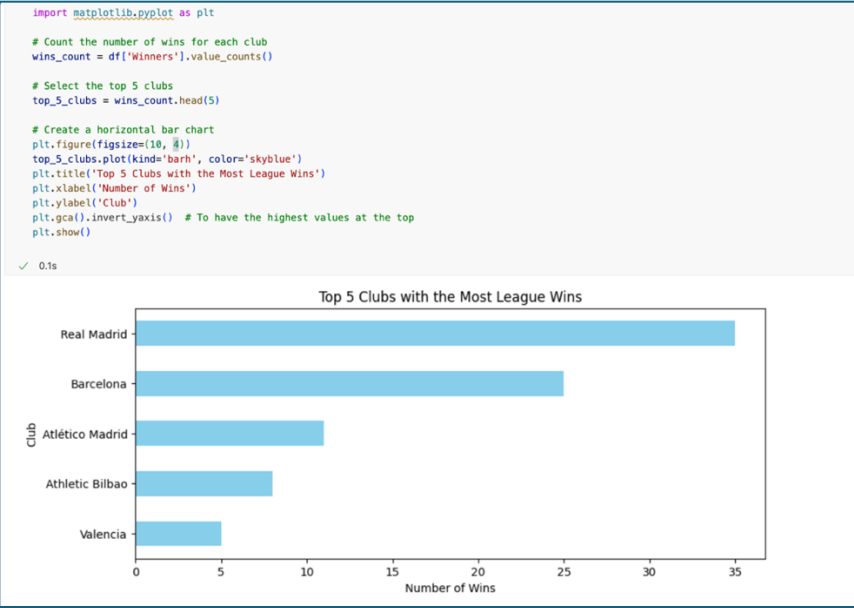
The bar chart clearly highlights the top 5 clubs with the most league wins in the Spanish Football League. At the forefront, Real Madrid leads the pack with a significant number of victories, demonstrating their consistent dominance in the league. Barcelona follows, showing a strong performance as well but not quite reaching the heights of their fierce rivals. Atlético Madrid, Athletic Bilbao, and Valencia round out the top 5, each contributing to the competitive spirit of Spanish football.
Real Madrid’s position at the top of the chart showcases their historical success and highlights why they are often considered one of the most successful clubs in football history. This data-driven analysis not only reinforces their legacy but also provides a clear visual representation of their achievements compared to other top clubs.
8. Conclusion
Web scraping is a powerful technique that can unlock a wealth of information from the internet. By following the steps outlined in this article, you can start scraping data for your own analysis projects. In this case, we used web scraping to gather historical data on the Spanish Football League, focusing on Real Madrid and Barcelona. By analyzing this data, we were able to determine the number of titles won by each club over the years.
By analyzing the historical data, you’ll be able to prove once and for all that Real Madrid is the most successful club in Spanish football, backed by data! With the right tools and techniques, web scraping can provide valuable insights that drive informed decisions and innovative solutions. So why not give it a try and see what valuable insights you can uncover?
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara