


Penerapan CNN (Convolutional Neural Network) dalam Mengidentifikasi Varietas Buah Berbasis Citra Digital
Sufriana
∙28 August 2024

Pengenalan jenis Buah merupakan faktor yang cukup penting bagi orang yang baru mengenal beberapa jenis buah yang jarang ditemui tentunya membuat bertanya tanya. Pada kasus kali ini dibuatnya sistem ini bertujuan untuk mempermudah orang untuk mengenal jenis buah. Pada sistem ini akan menggunakan metode CNN (Concolutional Netural Network) untuk mengklarifikasikan citra buah.
Convolution Neural Network (CNN) merupakan salah satu jenis algoritme Deep Learning yang dapat menerima input berupa gambar, menentukan aspek atau objek apa saja dalam sebuah gambar yang bisa digunakan mesin untuk “belajar” mengenali gambar, dan membedakan antara satu gambar dengan yang lainnya. CNN bekerja mirip seperti mata dan otak kita. Pertama, ia melihat gambar buah sebagai kumpulan piksel berwarna. Kemudian, seperti seorang koki yang sangat teliti, CNN mulai mengidentifikasi "cita rasa" visual dari setiap buah - bentuk, tekstur, warna, dan pola unik. Misalnya, CNN akan mengenali bahwa apel cenderung bulat dan memiliki tangkai kecil di atasnya, sementara pisang punya bentuk memanjang dan kuning. Setiap lapisan dalam CNN seperti tahapan dalam resep, semakin dalam semakin detail analisisnya.
Struktur dan Komponen Utama
CNN terdiri dari beberapa jenis lapisan yang masing-masing memiliki peran spesifik dalam proses ekstraksi fitur dan klasifikasi. Berikut adalah komponen utama dalam CNN:
Lapisan Konvolusi (Convolutional Layer):
-
Fungsi: Mendeteksi fitur-fitur lokal seperti tepi, tekstur, dan pola kecil dalam gambar.
-
Cara Kerja: Lapisan ini mengaplikasikan filter (atau kernel) yang berukuran lebih kecil dari gambar asli pada seluruh gambar. Filter ini melakukan operasi konvolusi, menghasilkan peta fitur yang menyoroti keberadaan fitur tertentu di berbagai lokasi dalam gambar.
-
Output: Setiap filter menghasilkan satu peta fitur, dan jumlah filter menentukan jumlah peta fitur.
Lapisan Pooling (Pooling Layer):
-
Fungsi: Mengurangi dimensi data (downsampling) untuk mengurangi jumlah parameter dan komputasi dalam jaringan serta mengontrol overfitting.
-
Cara Kerja: Pooling mengambil nilai maksimum (MaxPooling) atau rata-rata (AveragePooling) dari blok-blok kecil dalam peta fitur. Misalnya, MaxPooling dengan ukuran 2x2 akan mengambil nilai maksimum dari setiap blok 2x2 dalam peta fitur.
-
Output: Peta fitur dengan resolusi lebih rendah.
Lapisan Aktivasi (Activation Layer):
-
Fungsi: Memperkenalkan non-linearitas ke dalam model sehingga mampu mempelajari representasi yang lebih kompleks.
-
Cara Kerja: Fungsi aktivasi seperti ReLU (Rectified Linear Unit) menggantikan nilai negatif dengan nol dan membiarkan nilai positif tetap. Fungsi ini meningkatkan kemampuan model untuk mempelajari hubungan non-linear.
Lapisan Flatten (Flatten Layer):
-
Fungsi: Mengubah data dari bentuk dua atau tiga dimensi menjadi satu dimensi agar dapat dimasukkan ke lapisan fully connected.
-
Cara Kerja: Lapisan ini menghamparkan matriks fitur menjadi vektor.
Lapisan Fully Connected (Fully Connected Layer):
-
Fungsi: Melakukan klasifikasi berdasarkan fitur-fitur yang telah diekstraksi oleh lapisan sebelumnya.
-
Cara Kerja: Setiap neuron di lapisan ini terhubung ke semua neuron di lapisan sebelumnya, memungkinkan kombinasi fitur untuk menentukan output akhir.
-
Output: Nilai probabilitas untuk setiap kelas dalam tugas klasifikasi.
Lapisan Output (Output Layer):
-
Fungsi: Menghasilkan prediksi akhir model.
-
Cara Kerja: Lapisan ini biasanya menggunakan fungsi aktivasi softmax untuk tugas klasifikasi multi-kelas, mengubah skor menjadi probabilitas yang menjumlahkan hingga satu.
-
Output: Probabilitas untuk setiap kelas yang menunjukkan seberapa yakin model terhadap setiap kelas.
Kelebihan CNN dalam Klasifikasi Gambar
-
Ekstraksi Fitur Otomatis: Tidak memerlukan teknik ekstraksi fitur manual yang rumit, karena CNN secara otomatis mempelajari fitur penting dari data mentah.
-
Invarian Terhadap Translasi: Melalui pooling, CNN mampu mengenali objek meski mengalami translasi atau skala yang berbeda.
-
Kemampuan Generalisasi: Dengan teknik regularisasi seperti dropout, CNN dapat mengurangi overfitting dan meningkatkan kemampuan generalisasi.
CNN telah menjadi standar emas dalam berbagai aplikasi visi komputer, termasuk pengenalan objek, deteksi wajah, dan analisis citra medis, karena kemampuannya yang luar biasa dalam memahami dan mengklasifikasikan gambar secara efektif dan efisien.
Contoh Penggunaan Convolutional Neural Network (CNN) di Python untuk Klasifikasi Gambar Buah
Mempersiapkan Data
Mempersiapkan data dalam 1 folder yang sama, dengan mengklasifikasikan tiap kelompok gambar dalam 1 folder.
 Gambar 1. Contoh data
Gambar 1. Contoh data
Pastikan seluruh data memiliki ukuran yang sama, ukuran yang digunakan disini adalah 168x168 px. Untuk jumlah dataset masing-masing buah adalah 20 gambar.
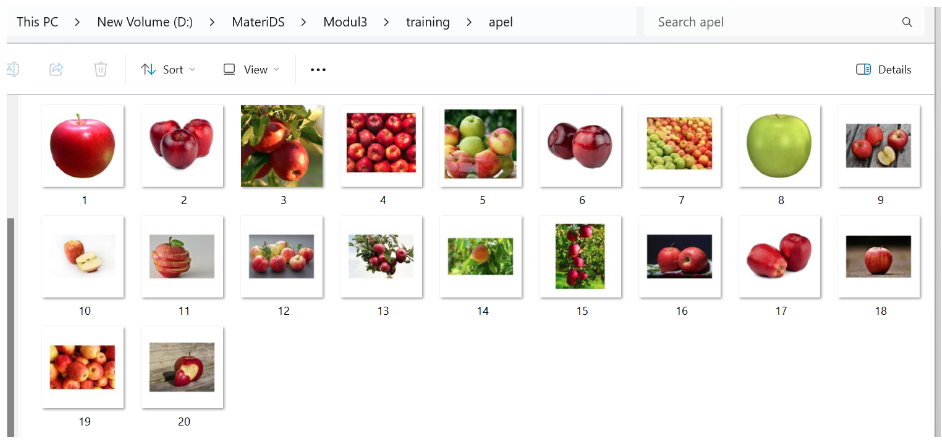 Gambar 2. Data buah apel
Gambar 2. Data buah apel
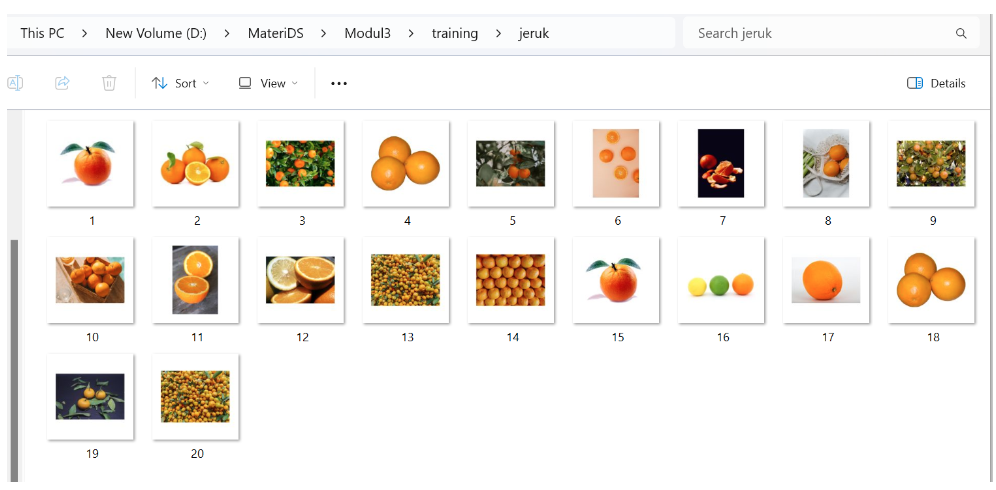 Gambar 3. Data buah jeruk
Gambar 3. Data buah jeruk
Instalasi
Pertama, kita perlu menginstal TensorFlow terlebih dahulu. Menginstal TensorFlow diperlukan untuk mengembangkan dan menjalankan model machine learning dan deep learning. Berikut adalah langkah-langkah yang bisa diikuti:
 Gambar 4. Install TensorFlow
Gambar 4. Install TensorFlow
Import Library
Setelah berhasil menginstal TensorFlow, langkah berikutnya adalah mengimpor pustaka dan modul yang diperlukan ke dalam skrip atau notebook Python. Berikut adalah beberapa pustaka yang biasanya diimpor saat bekerja dengan TensorFlow, terutama saat membangun dan melatih model deep learning:
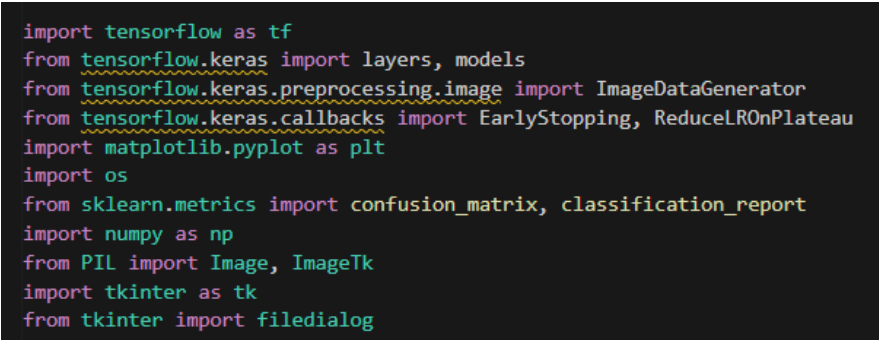 Gambar 5. Import library
Gambar 5. Import library
Memeriksa Dataset
Bertujuan untuk memeriksa distribusi kelas dalam dataset gambar yang tersimpan di direktori. Fungsi ini menghitung jumlah gambar dalam setiap subdirektori, di mana setiap subdirektori mewakili satu kelas dalam dataset klasifikasi gambar.
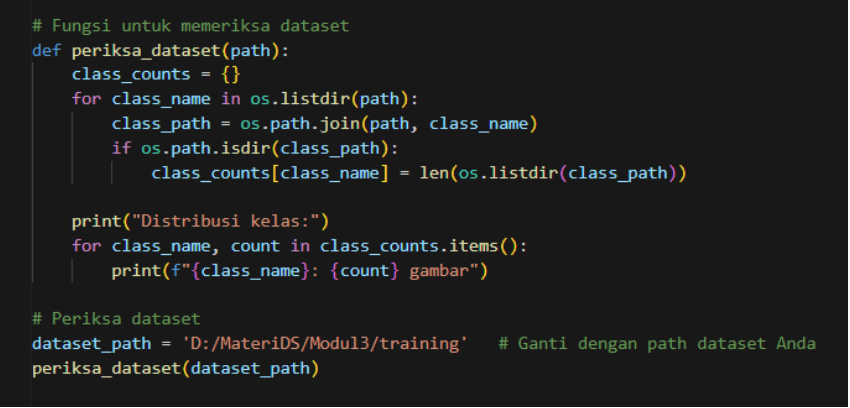 Gambar 6. Memeriksa dataset
Gambar 6. Memeriksa dataset
Persiapan Data
Kode berikut menyiapkan data untuk pelatihan model machine learning dengan melakukan augmentasi data dan memisahkan dataset menjadi set pelatihan dan validasi:
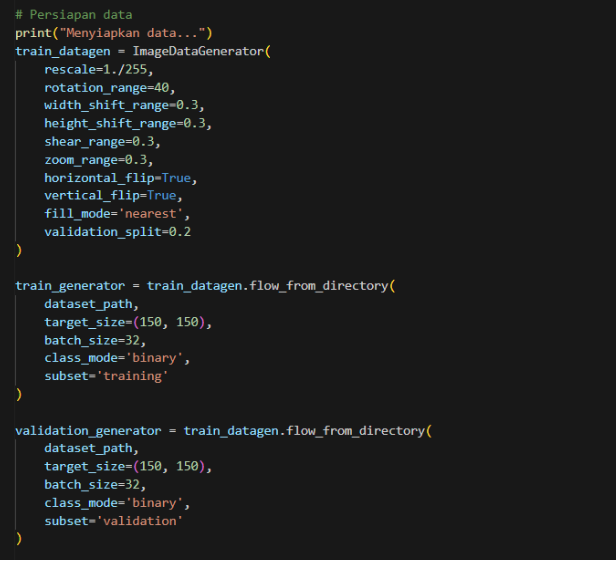 Gambar 7. Persiapan data
Gambar 7. Persiapan data
Membagun dan Melatih Model
Berikut adalah kode membangun dan melatih model CNN:
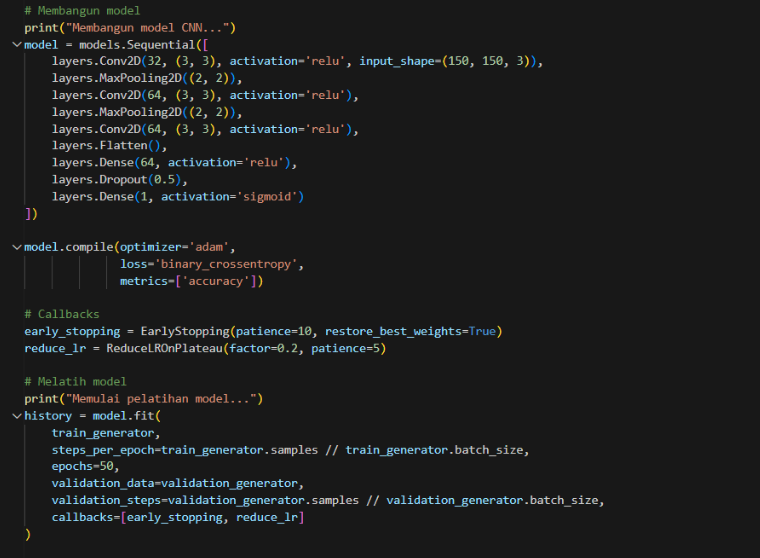 Gambar 8. Membangun dan melatih model
Gambar 8. Membangun dan melatih model
Evaluasi Model dan Visualisasi Hasil Pelatihan
Evaluasi Model dan Visualisasi Hasil Pelatihan
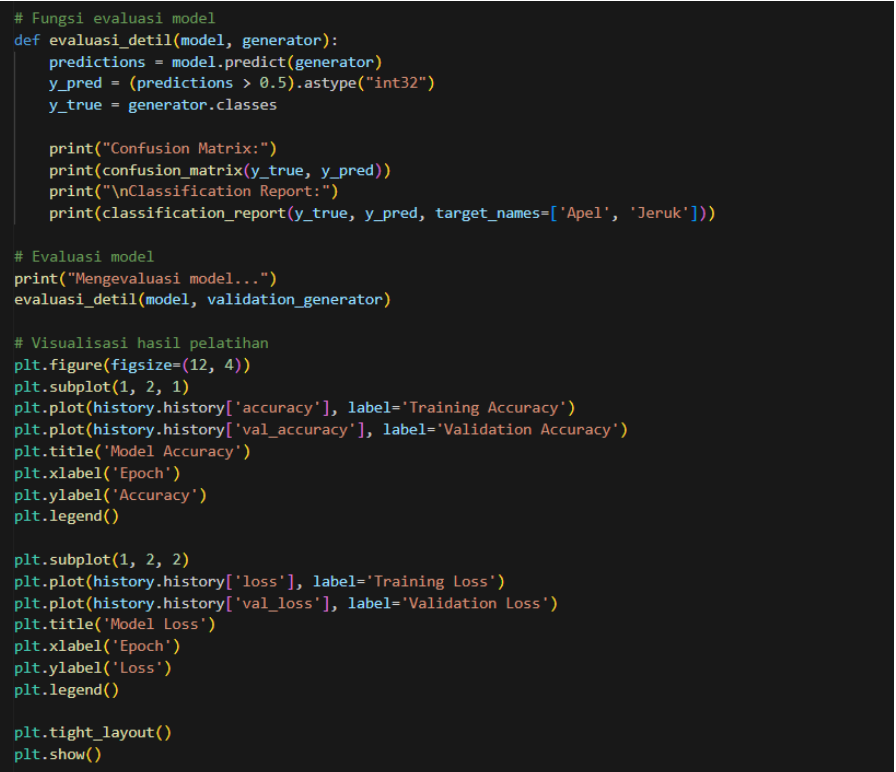 Gambar 9. Evaluasi model dan visualisasi hasil pelatihan
Gambar 9. Evaluasi model dan visualisasi hasil pelatihan
Dari kodingan tersebut didapati hasil epoch dan akurasi yang dapat dilihat pada gambar di bawah ini.
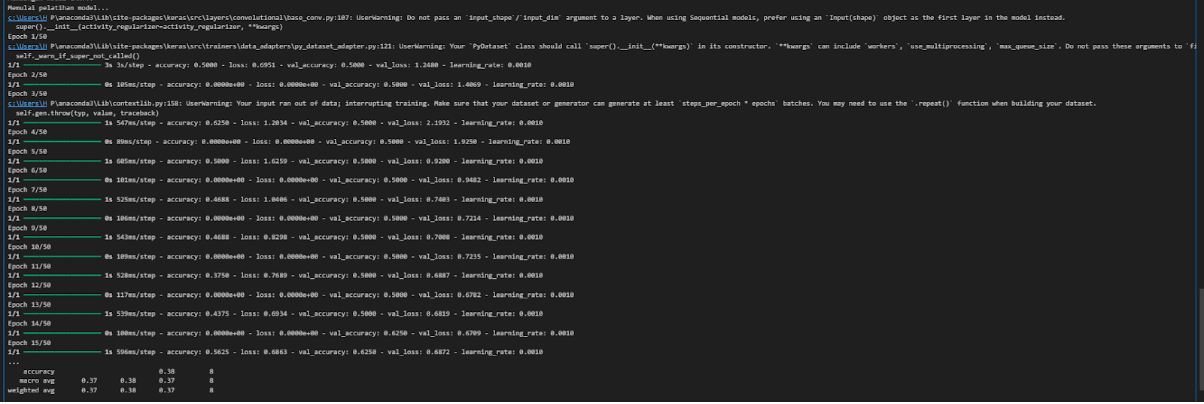 Gambar 10. Hasil pelatihan model
Gambar 10. Hasil pelatihan model
Menyimpan Model
Pada kode dibawah, kita menyimpan model yang telah dilatih ke dalam sebuah file dengan format HDF5 menggunakan metode model.save(). Ini adalah langkah penting dalam pengembangan machine learning, karena memungkinkan kita menyimpan model untuk digunakan nanti tanpa perlu melatih ulang dari awal. Berikut adalah kodenya:
 Gambar 10. Menyimpan model
Gambar 10. Menyimpan model
Pembuatan GUI(Graphical User Interface) Aplikasi Klasifikasi Buah
Aplikasi ini memungkinkan pengguna untuk memilih gambar buah, dan kemudian sistem akan mengklasifikasikan jenis buah tersebut menggunakan model machine learning yang telah dilatih sebelumnya, menampilkan hasilnya dalam antarmuka yang user-friendly.
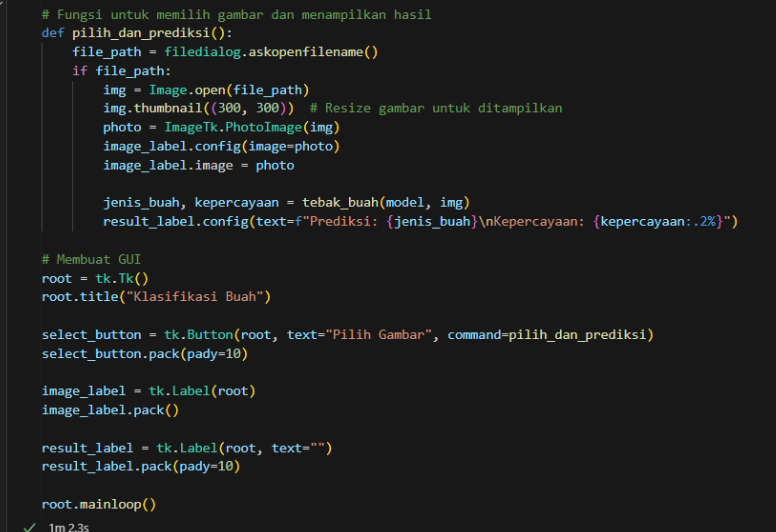 Gambar 11. Pembuatan GUI Aplikasi Klasifikasi Buah
Gambar 11. Pembuatan GUI Aplikasi Klasifikasi Buah
Tampilan user-friendly terlihat seperti Gambar 12. Tampilan awal aplikasi klasifikasi buah menampilkan antarmuka pengguna yang minimalis dan intuitif. Terdapat sebuah tombol utama bertuliskan 'Pilih Gambar' yang memungkinkan pengguna untuk memilih file gambar buah yang ingin diklasifikasikan. Desain antarmuka yang bersih ini memudahkan pengguna untuk fokus pada fungsi utama aplikasi tanpa gangguan visual yang tidak perlu. Saat tombol 'Pilih Gambar' ditekan, pengguna akan diarahkan untuk memilih file gambar dari perangkat mereka. Setelah gambar dipilih, aplikasi akan memproses gambar tersebut dan menampilkan hasil klasifikasi jenis buah beserta tingkat kepercayaan prediksinya.
 Gambar. 12. Antarmuka grafis (GUI) untuk aplikasi klasifikasi buah
Gambar. 12. Antarmuka grafis (GUI) untuk aplikasi klasifikasi buah
Hasil Prediksi
Setelah melalui beberapa tahapan, dilakukan pengujian prediksi. Gambar yang digunakan adalah gambar Apel.
 Gambar 13. Hasil Prediksi
Gambar 13. Hasil Prediksi
Dalam contoh yang ditunjukkan, hasil prediksi menampilkan bahwa model berhasil mengklasifikasikan gambar sebagai 'Apel' dengan tingkat kepercayaan yang sangat tinggi, yaitu 92.44%. Hal ini menandakan bahwa model memiliki keyakinan kuat bahwa buah dalam gambar adalah apel, bukan jeruk.
Dalam konteks klasifikasi biner antara apel dan jeruk, model memprediksi gambar baru sebagai “Apel” dengan probabilitas tertinggi di antara semua kelas. Ini sesuai dengan gambar yang digunakan. Pertama, model menunjukkan akurasi tinggi dalam membedakan karakteristik visual apel dari jeruk. Kedua, tingkat kepercayaan di atas 90% mengindikasikan bahwa model memiliki sedikit keraguan dalam klasifikasinya. Selain itu, model berhasil mengenali fitur-fitur khas apel seperti bentuk bulat, warna merah, dan tekstur kulit yang khas, yang membedakannya dari jeruk.
Kinerja model yang ditunjukkan mengindikasikan bahwa ia telah dilatih dengan baik untuk membedakan antara dua kelas buah ini. Namun, meskipun dalam kasus ini prediksi sangat akurat, penting untuk terus menguji model dengan berbagai variasi gambar apel dan jeruk. Hal ini bertujuan untuk memastikan konsistensi dan kehandalan model dalam situasi yang lebih beragam, sehingga aplikasi dapat memberikan hasil yang akurat dalam berbagai kondisi penggunaan.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara