


Optimalisasi Model Multi-Target Regression: Memahami Perbedaan antara MultiOutputRegressor dan Regressor Chain di Scikit-Learn
Yusuf Sidharta
∙30 August 2024

Apa Itu Multi-Target Regression?
Di dalam pembuatan sebuah model regresi, seorang data scientist sering kali bertemu dengan multiple regression, yaitu model regresi yang targetnya atau variabel dependennya dipengaruhi oleh lebih dari satu fitur atau variabel independen. Tidak hanya dari model-model linear, model-model regressor lain, baik yang berbasis tree maupun k-nearest neighbors, juga cenderung menggunakan lebih dari satu fitur untuk menentukan nilai regresi dari sebuah target.
Tapi, jika ada model yang menggunakan lebih dari satu fitur, apakah ada model yang mempunyai lebih dari satu target? Karena dalam dunia nyata, ada beberapa kasus di mana hanya menggunakan model machine learning dengan satu target saja tidak bisa menangkap esensi dari sebuah data. Sebagai contoh, data-data yang berhubungan dengan meteorologi dan geofisika. Seringkali prediksi mengenai suatu data yang berhubungan dengan iklim, cuaca, maupun lingkungan akan lebih memiliki nilai jika bisa diprediksi secara bersamaan. Beberapa industri lain seperti industri keuangan dan industri kesehatan juga menggunakan model regresi yang mempunyai lebih dari satu target, yang diprediksi secara bersamaan.
Model regresi yang mempunyai lebih dari satu variabel target disebut dengan multi-output regression atau multi-target regression. Pada kelompok model ini, setiap variabel target diprediksi secara terpisah-pisah dengan sebuah model yang bisa memprediksi semua variabel target tersebut secara akurat dan bersamaan. Ada beberapa model yang algoritmanya bisa memprediksi lebih dari satu variabel target, seperti linear regression dan decision trees. Ada juga model-model yang memerlukan sedikit modifikasi untuk bisa melakukan prediksi multi-target.
Ada beberapa aspek kunci yang harus diperhatikan dalam menyusun multi-target regression model. Pertama, dataset yang digunakan harus mempunyai lebih dari satu variabel target. Variabel-variabel target ini bisa saja independen satu sama lain, ataupun mempunyai hubungan yang dapat menyebabkan model menjadi sangat kompleks. Kemudian, metrik yang digunakan tidak jauh berbeda dengan model regresi biasa. Model dapat dievaluasi menggunakan metrik-metrik seperti MSE, MAE, MAPE, R-square, dan metrik-metrik lain yang digunakan untuk mengevaluasi sebuah model regresi. Metrik-metrik ini tidak menilai error dari target satu per satu, tapi menilai error dari semua target secara keseluruhan menggunakan rata-rata. Namun, jika diperlukan, error masing-masing dapat juga dilihat untuk setiap target yang ada di dalam model. Terakhir, permodelan yang lebih kompleks dari model regresi biasa berarti ada risiko overfitting yang lebih tinggi, sehingga memerlukan tingkat kehati-hatian yang lebih tinggi dalam menentukan model yang akan digunakan.
Bagaimana Cara Melakukan Multi-Target Regression?
Teknik Multi-Target Regression
Ada beberapa teknik yang dapat dilakukan dalam membuat model multi-target regression, yaitu:
- Ensemble Methods
Model-model ensemble, terutama Random Forests dan Gradient Boosting dapat melakukan multi-target regression dengan bantuan class bernama sklearn.multioutput.MultiOutputRegressor.
- Deep Learning
Model-model deep learning seperti neural networks dapat dikembangkan untuk menyelesaikan masalah multi-target regression, terutama dalam memecahkan hubungan antara fitur-fitur yang ada dengan variabel target, baik secara secara target individu maupun hubungan masing-masing target.
- Mengubah Kebutuhan Menjadi Single Output
Cara lain yang sering digunakan adalah mengubah model menjadi single output regression. Masalah disederhanakan agar solusi dapat diberikan dari satu nilai prediksi.
Implementasi Multi-Target Regression pada Python
Menggunakan Inherent Model
Dalam implementasi multi-target regression, dalam beberapa model belum perlu melakukan hal khusus. Selama data target konsisten, melakukan multi-target regression dengan model-model dasar seperti linear regression, k-nearest neighbors, dan decision tree, maupun model ensemble seperti random forests dan gradient booster dapat langsung dilakukan.
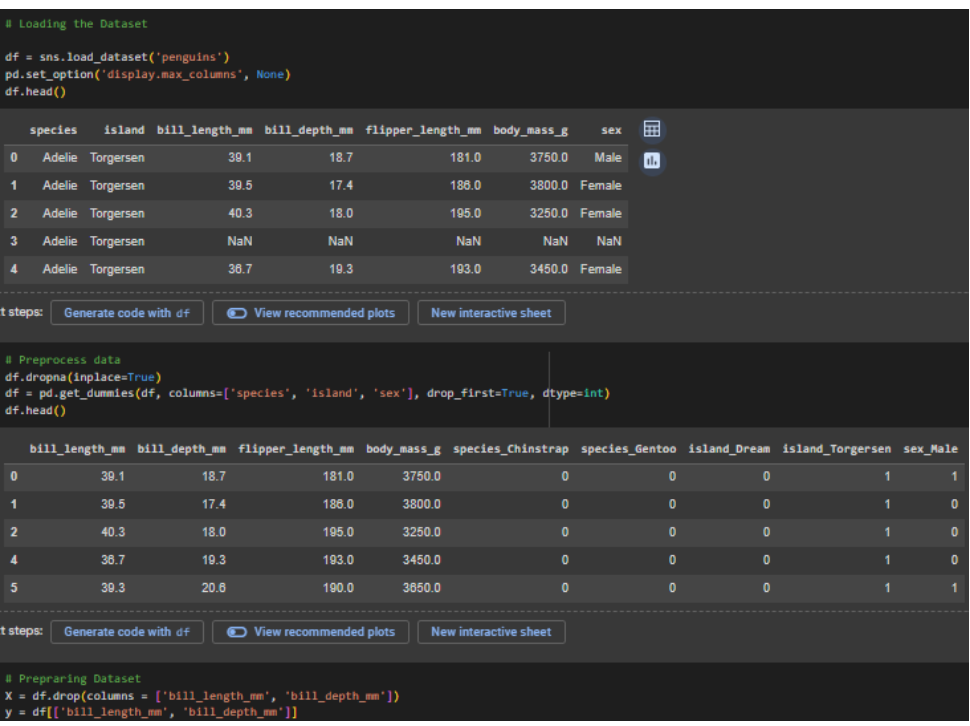 Gambar 1. Melakukan import dataset ‘penguins’ dari library Seaborn
Gambar 1. Melakukan import dataset ‘penguins’ dari library Seaborn
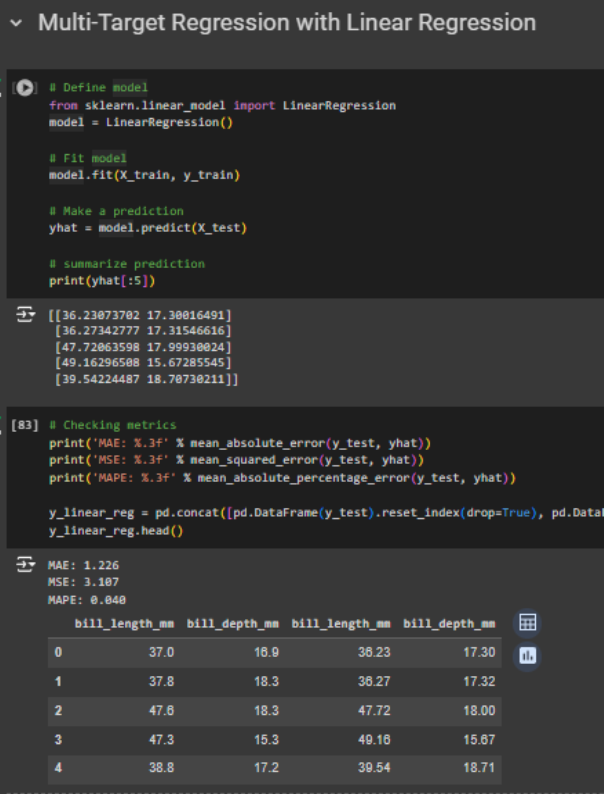 Gambar 2. Membuat model multi-target regression menggunakan linear regression
Gambar 2. Membuat model multi-target regression menggunakan linear regression
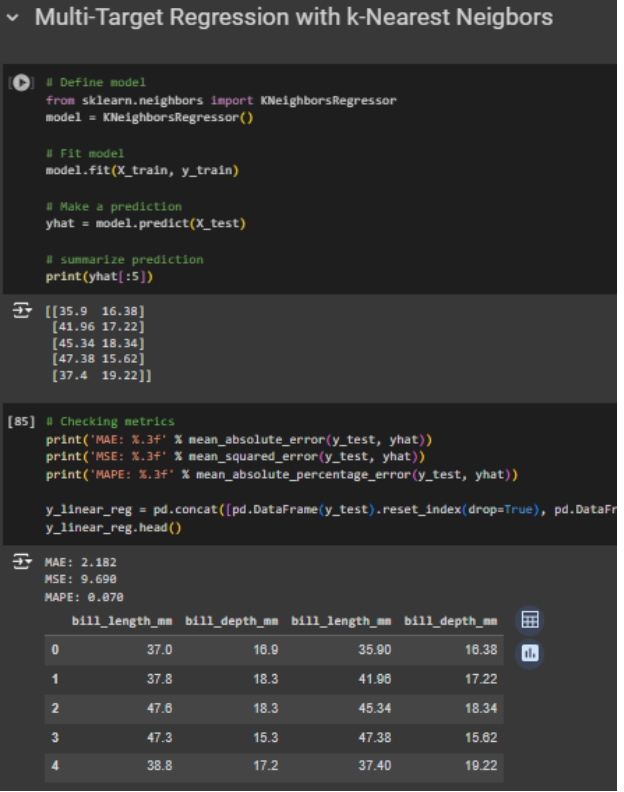 Gambar 3. Membuat model multi-target regression menggunakan k-nearest neighbors
Gambar 3. Membuat model multi-target regression menggunakan k-nearest neighbors
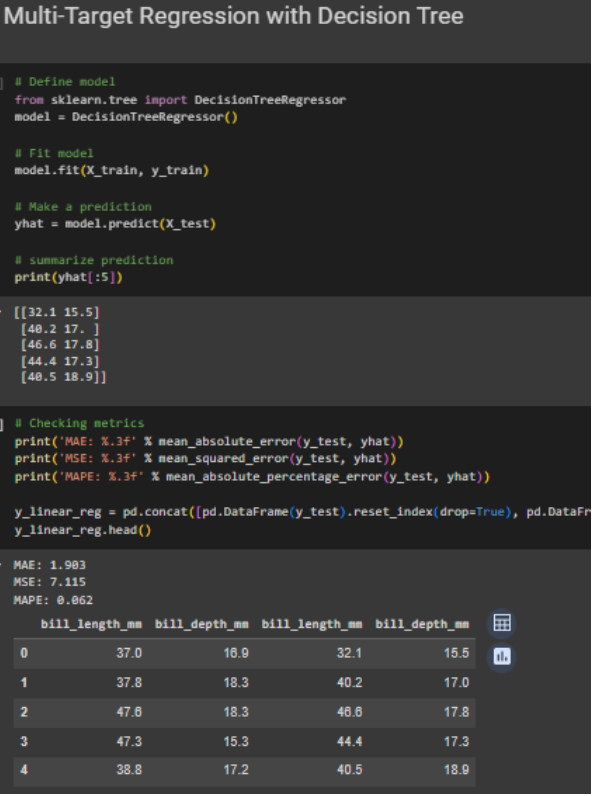 Gambar 4. Membuat model multi-target regression menggunakan decision tree
Gambar 4. Membuat model multi-target regression menggunakan decision tree
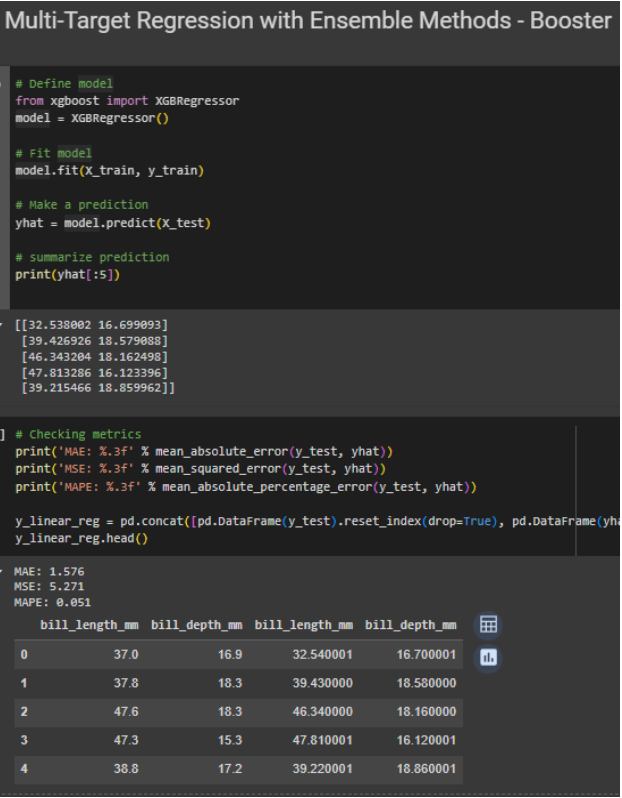 Gambar 5. Membuat model multi-target regression menggunakan booster method
Gambar 5. Membuat model multi-target regression menggunakan booster method
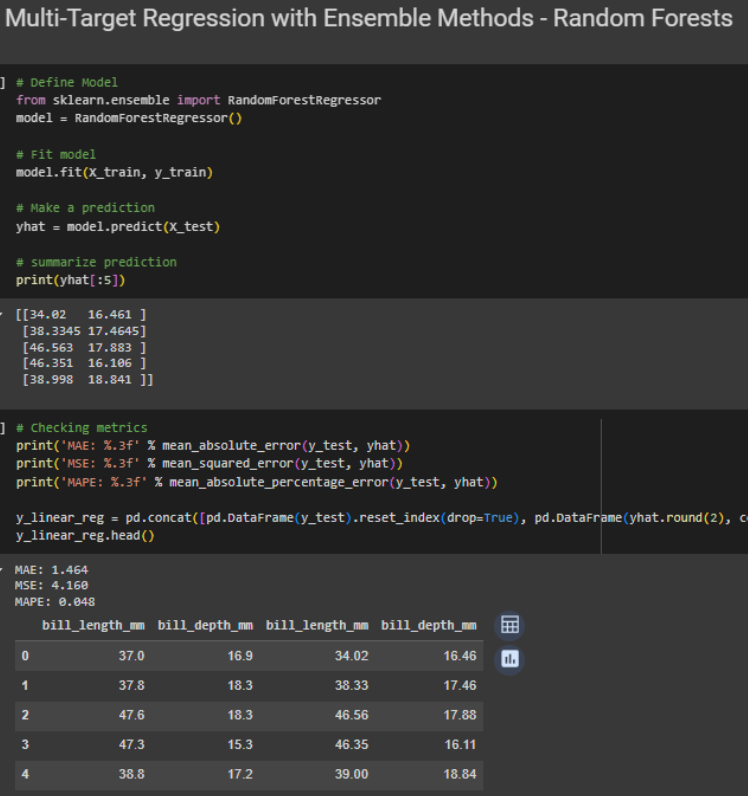 Gambar 6. Membuat model multi-target regression menggunakan random forest method
Gambar 6. Membuat model multi-target regression menggunakan random forest method
Dapat dilihat dari gambar-gambar di atas, bahwa tidak ada perbedaan syntax antara melakukan regresi biasa dengan multi-target regression. Perbedaan mungkin dapat dilihat pada dataset targetnya, serta nilai prediksi yang pada kasus ini masing-masing mempunyai dua kolom. Tentunya perlu diperhatikan juga metrik evaluasi dari masing-masing model, apakah dengan inherent model, hasil evaluasi metriknya sudah cukup baik. Jika model terlalu kompleks untuk menggunakan inherent model, atau ada sebuah hubungan antar target dalam masalah regresi, perlu menggunakan class MultiOutputRegressor dari sklearn.multioutput.
Menggunakan MultiOutputRegressor
Tidak semua inherent model dapat langsung melakukan multi-target regression. Selain itu, terkadang performa inherent model tidak terlalu bagus, sehingga diperlukan perlakuan tambahan. Ada dua langkah tambahan yang dapat diambil, tergantung dari apakah masing-masing target independen atau tidak. Jika semua target independen, maka menggunakan MultiOutputRegressor dapat meningkatkan performa model. Class dari library sklearn.multioutput ini akan membagi regresi sesuai dengan jumlah target, dan dalam banyak kasus menjadi sebuah baseline untuk mengevaluasi performa sebuah model.
Untuk menggunakan MultiOutputRegressor, penggunaannya dapat mengikuti syntax berikut:
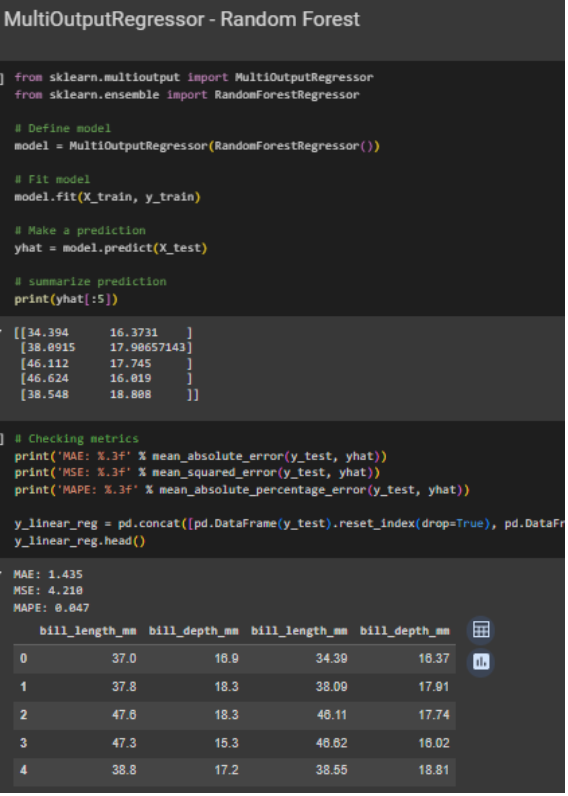 Gambar 7. Membuat model multi-target regression menggunakan model random forest sebagai model dan wrapper MultiOutputRegressor
Gambar 7. Membuat model multi-target regression menggunakan model random forest sebagai model dan wrapper MultiOutputRegressor
Perbedaan yang paling mencolok hanyalah penggunaan MultiOutputRegressor, yang berfungsi sebagai wrapper atau pembungkus model. Untuk syntax maupun penggunaan cross-validation dan hyperparameter tuning, ada sedikit perbedaan karena sifat dari masing-masing langkah di atas.
MultiOutputRegressor memiliki dua parameter utama, yaitu:
- estimator : objek model yang digunakan sebagai model regresi.
- n-jobs : jumlah thread atau process yang digunakan untuk proses komputasi.
Jika ingin melakukan hyperparameter tuning, parameter yang ingin diubah dalam grid search ataupun random search perlu ditambahkan _‘_estimator’ di antara nama langkah di dalam pipeline dan parameter model yang ingin diubah. Sebagai contoh, untuk melakukan hyperparameter tuning dari kedalaman maksimum random forest, parameter yang diuji dapat ditambahkan key ‘multi_output__estimator__max_depth’ di dalam dictionary ‘param_grid’ ketika melakukan grid search.
Menggunakan RegressorChain
Class MultiOutputRegressor di atas dapat digunakan ketika variabel-variabel target dari model diasumsikan (atau memang) independen satu sama lain. Namun, bagaimana dengan dataset yang variabel-variabel targetnya memiliki korelasi yang tinggi?
Contohnya saja pada dataset penguins yang tersedia di library Seaborn. Pada artikel ini, dataset tersebut digunakan dengan variabel-variabel targetnya adalah ‘bill_length_mm’ dan ‘bill_depth_mm’, yang di mana kedua variabel tersebut memiliki hubungan meskipun korelasinya lemah.
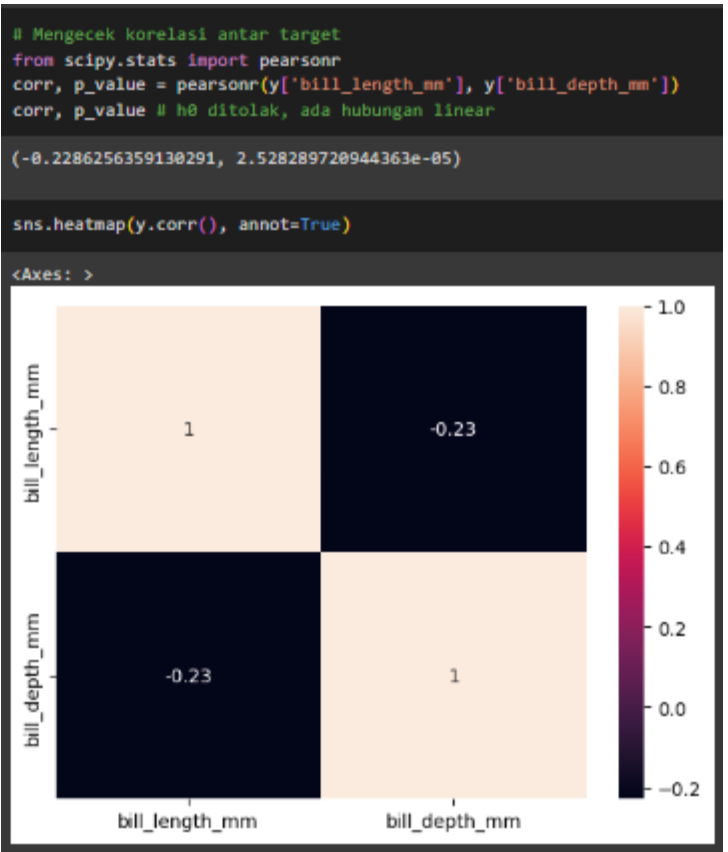 Gambar 8. Uji korelasi antara kedua variabel target ‘bill_length_mm’ dan ‘bill_depth_mm’
Gambar 8. Uji korelasi antara kedua variabel target ‘bill_length_mm’ dan ‘bill_depth_mm’
Meskipun sebenarnya pembuatan model ini dapat dilakukan dengan inherent model ataupun dengan class MultiOutputRegressor, sebenarnya library scikit-learn juga sudah menyiapkan wrapper lain yang lebih cocok digunakan untuk kasus ini bernama Regressor Chain. Class Regressor Chain ini bekerja dengan cara mengerjakan model prediksi secara berurutan, dengan detail seperti ilustrasi di bawah:
- Regresi 1 : Memprediksi y1 dari fitur
- Regresi 2 : Memprediksi y2 dari fitur DAN y1
- Regresi 3 : Memprediksi y3 dari fitur DAN y1, y2
- dst.
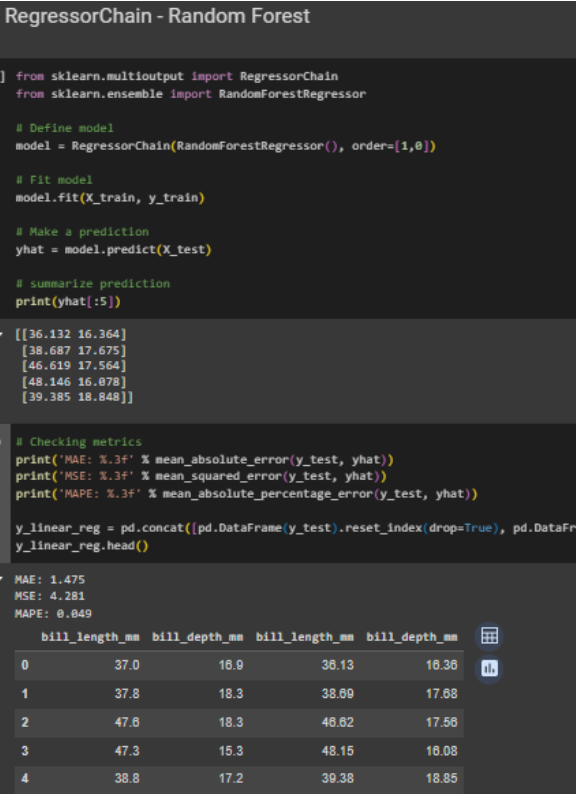 Gambar 9. Membuat model multi-target regression menggunakan model random forest sebagai model dan wrapper RegressorChain
Gambar 9. Membuat model multi-target regression menggunakan model random forest sebagai model dan wrapper RegressorChain
Seperti pada metode MultiOutputRegressor, penggunaan RegressorChain juga dapat langsung dilakukan sebagai wrapper dan tidak mengganggu proses cross-validation maupun hyperparameter tuning. Sedikit berbeda dengan MultiOutputRegressor, syntax di dalam param_grid ditambahkan _‘_base_estimator’ daripada _‘_estimator’ saja. RegressorChain-nya sendiri juga dapat dilakukan hyperparameter tuning, karena ada beberapa parameter di dalam class tersebut yang dapat memengaruhi model akhir. Parameter yang ada di dalam RegressorChain adalah:
-
base_estimator : objek model yang digunakan sebagai model regresi.
-
order : urutan variabel target mana yang dikerjakan terlebih dahulu, default sesuai urutan di data; order bisa menggunakan ‘random’ untuk mengacak urutan pengerjaan variabel target.
-
cv : menentukan apakah menggunakan prediksi yang sudah divalidasi atau langsung hasil prediksi sebagai hasil dari variabel target pada chain sebelumnya.
-
random_state : pengaplikasian random_state untuk urutan pengerjaan variabel target jika parameter ‘order’ bernilai ‘random’.
Dalam mengerjakan model regresi yang memiliki lebih dari satu variabel target, seorang data scientist dapat memilih untuk menggunakan model yang inherent atau menggunakan wrapper MultiOutputRegressor atau RegressorChain sesuai dengan kebutuhan data. Ada beberapa hal yang perlu diperhatikan dalam penggunaanya, terutama apakah variabel-variabel target independen atau tidak, dan syntax maupun beban komputasi yang sedikit berbeda dalam melakukan cross-validation dan hyperparameter tuning.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara