


Aplikasi Library NetworkX dan Pyvis Dalam Phyton Untuk Deteksi Tindak Pencucian Uang
Zaky Indra Satria Putra
∙19 March 2024

Pengenalan
Sistem pemantauan transaksi tradisional memiliki kemampuan untuk mendeteksi aktivitas mencurigakan pada akun individu pelanggan. Ketika peringatan ditandai pada rekening, penyidik harus mengikuti rantai pergerakan dana untuk memeriksa apakah sumber dana mencurigakan berasal dari rekening lain di lembaga tersebut, serta meninjau akun terkait.
Selain analisis aliran dana, diperlukan pemeriksaan terhadap akun lain di institusi yang mungkin memiliki karakteristik KYC (Know Your Customer) serupa dengan subjek peringatan, seperti pemegang saham, direktur, atau pengacara yang sama, alamat, email, atau nomor telepon yang identik. Pemeriksaan terhadap akun terkait ini juga perlu dilakukan.
KYC dapat didefinisikan sebagai proses identifikasi dan verifikasi pelanggan oleh lembaga keuangan atau entitas bisnis untuk memahami dan mengumpulkan informasi lengkap tentang identitas, kegiatan, dan risiko yang terkait dengan pelanggan Kedua skenario aliran dana dan investigasi tersebut mencerminkan contoh analisis jaringan, dimana aliran dana atau atribut KYC bersama digunakan sebagai tautan untuk mengidentifikasi akun tambahan yang mungkin terlibat dalam operasi kriminal yang sama.
- Analisis jaringan memiliki peran baru-baru ini yang membantu penyelidik untuk:
- Mengurangi upaya dalam mengidentifikasi akun terkait, termasuk membantu mengidentifikasi akun utama dalam sindikat kriminal.
- Mengurangi beban kerja dalam pemantauan transaksi dari perspektif institusi, karena memungkinkan peninjauan akun-akun terkait secara berkelompok daripada satu per satu.
- Menyederhanakan visualisasi jaringan.
- Melalui pendekatan ini, analisis jaringan menjadi alat yang efektif untuk mengoptimalkan proses identifikasi dan penanganan potensi kegiatan kriminal dalam lingkungan keuangan.
Pendefinisian Masalah
Eksplorasi ini dapat menjadi tantangan karena penyelidik harus meninjau akun satu per satu untuk membangun jaringan. Setelah tampilan jaringan diperoleh, penyelidik juga perlu merangkum temuan tersebut dengan grafik jaringan yang mungkin sangat kompleks, terutama jika ukuran jaringannya besar. Bagaimana analisis jaringan dapat dilakukan menggunakan Python, dengan menggunakan pustaka NetworkX dan Pyvis, untuk mengatasi keterbatasan ini?
Metode Penyelesaian
Dalam proyek ini, akan digunakan utamanya tiga perpustakaan berikut:
- Pandas: untuk manipulasi data.
- NetworkX: untuk konstruksi jaringan, pengukuran sentralitas, dan deteksi komunitas.
- Pyvis: untuk pembuatan grafik jaringan interaktif. Alur kerja proyek ini dapat dijelaskan sebagai berikut:
- Menyiapkan data node, edge, beserta atributnya menggunakan pandas.
- Mengimpor data yang telah disiapkan ke dalam networkx untuk membangun objek jaringan.
- Mengimpor objek jaringan ke dalam pyvis.
- Visualisasi grafik jaringan dengan menggunakan pyvis.
Konfigurasi Projek
Dataset
Pada penelitian ini akan mendemonstrasikan analisis jaringan menggunakan Dataset Contoh IBM AMLSim yang tersedia di Kaggle. Ini adalah data transaksi perbankan sintetis bersama dengan serangkaian pola pencucian uang yang diketahui terutama untuk tujuan pengujian model machine learning dan algoritma graf.
Kemudian akan digunakan transactions.csv, ini adalah dataset yang cukup besar. Sebelum
beralih ke dataset lengkap, mari berkenalan terlebih dahulu dengan dataset sampel transactions_sample.csv untuk mengenal lebih dekat networkx dan pyvis.
Persiapan Data Node dan Edge
Untuk membaca file transactions_sample.csv ke dalam dataframe pandas, langkah-langkahnya dapat dilakukan sebagai berikut:

Terdapat 1.850 catatan dalam txn_small. Setiap catatan mewakili satu transaksi. Hanya terdapat transfer intra-institusi dalam dataset sintetis ini.
Kolom SENDER_ACCOUNT_ID menunjukkan pelanggan yang mentransfer dana, dan kolom RECEIVER_ACCOUNT_ID menunjukkan pelanggan yang menerima dana. Terakhir, kolom
TX_AMOUNT menunjukkan jumlah transaksi tersebut.
Untuk mentransformasikan data transaksi ke dalam bentuk node dan edge, kita perlu mengelompokkan dataframe dengan menggunakan SENDER_ACCOUNT_ID dan RECEIVER_ACCOUNT_ID:

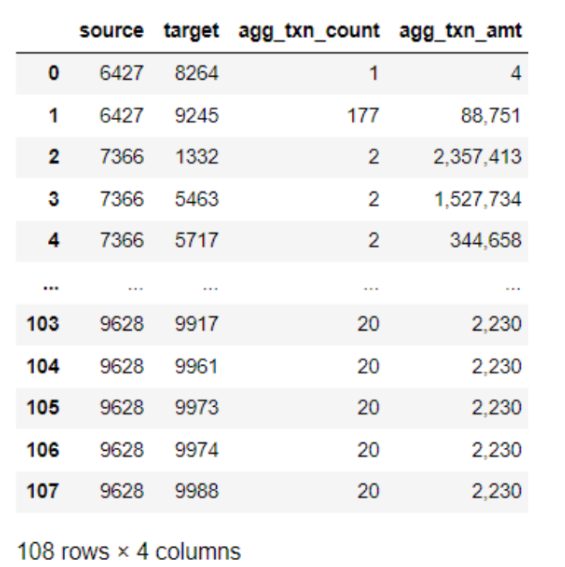
Setelah operasi pengelompokan, setiap baris mewakili transaksi yang diagregasi antara sumber (pemberi) dan tujuan (penerima). Sementara itu, agg_txn_count dan agg_txn_amt mewakili jumlah dan jumlah transaksi yang diagregasi di antara keduanya secara berturut-turut.
Dengan kata lain, node-node sekarang dikumpulkan di bawah kolom source dan target, dan edge direpresentasikan oleh setiap baris dalam dataframe. Selain itu, kolom agg_txn_count dan agg_txn_amt mewakili atribut dari setiap edge.
Membangun Jaringan dengan NetworkX
Setelah data node dan edge telah disiapkan, kita siap untuk mengimpornya ke networkx untuk konstruksi jaringan. Untuk mengimpor dataframe ke networkx, kita dapat menggunakan nx.from_pandas_edgelist():
Objek jaringan disimpan dalam variabel G. Untuk mengakses informasi node dan edge di bawah G, kita dapat menggunakan .nodes dan .edges. Selain itu, kita dapat melewati argumen data=True di .nodes dan .edges untuk melihat atribut node/edge:
Setiap node disimpan dalam bentuk tuple di mana elemen pertama adalah id node dan elemen kedua adalah kamus atribut node. Kamus atribut masih kosong karena kita belum menetapkan atribut apa pun pada node hingga saat ini.
Demikian pula, setiap edge disimpan dalam bentuk tuple di mana elemen pertama adalah node sumber dan elemen kedua adalah node tujuan. Elemen ketiga adalah kamus atribut edge yang saat ini masih kosong. Tata letak jaringan akhirnya terutama dikendalikan oleh kamus atribut node/edge yang akan kita mainkan lebih lanjut.
Menggambar Grafik Jaringan dengan NetworkX dan Pyvis
Baik networkx maupun pyvis mampu menghasilkan grafik jaringan. Untuk menghasilkan grafik jaringan menggunakan networkx, kita dapat menggunakan nx.draw():
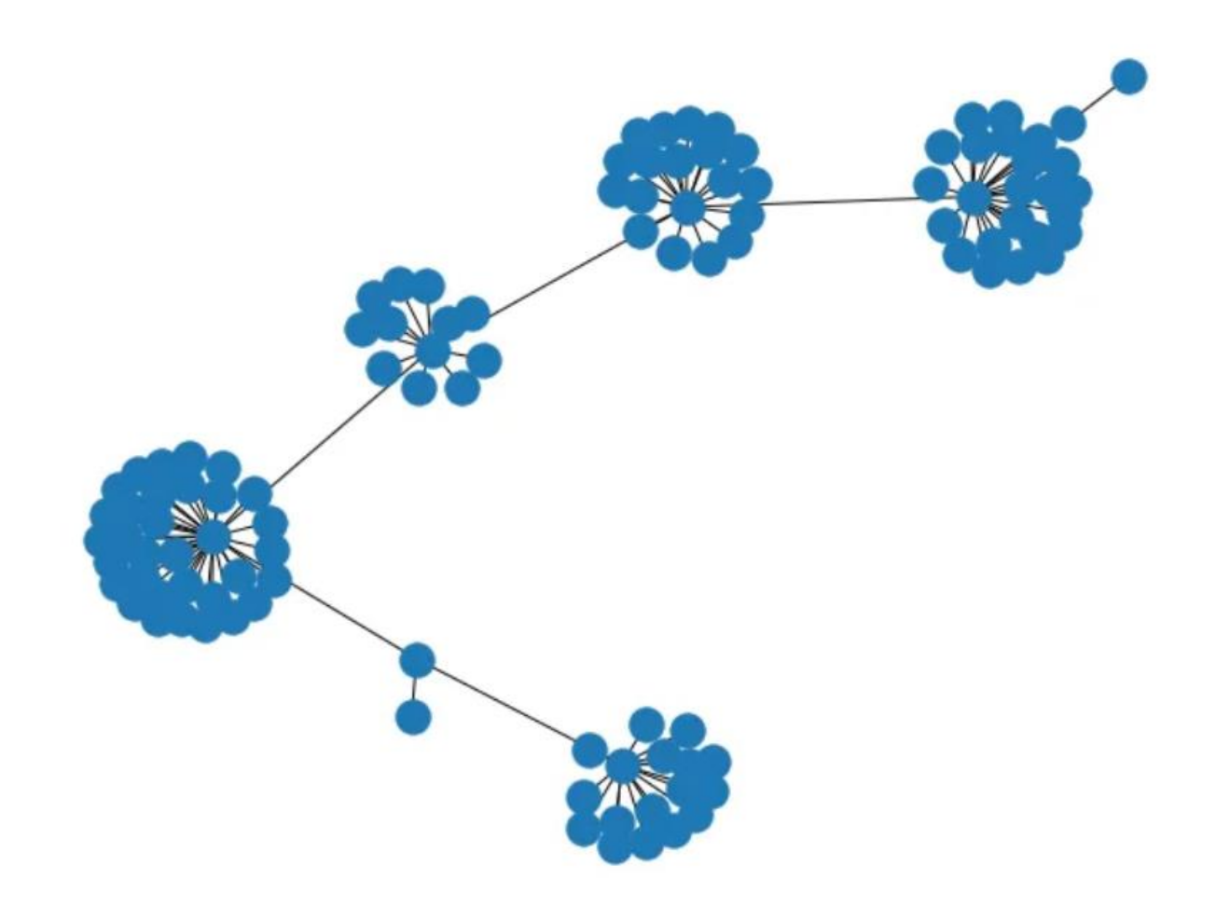
Grafik jaringan menunjukkan beberapa struktur dan hubungan antar node. Namun, tata letaknya tidak terlalu indah. Mari coba visualisasikan grafik jaringan dengan pyvis.
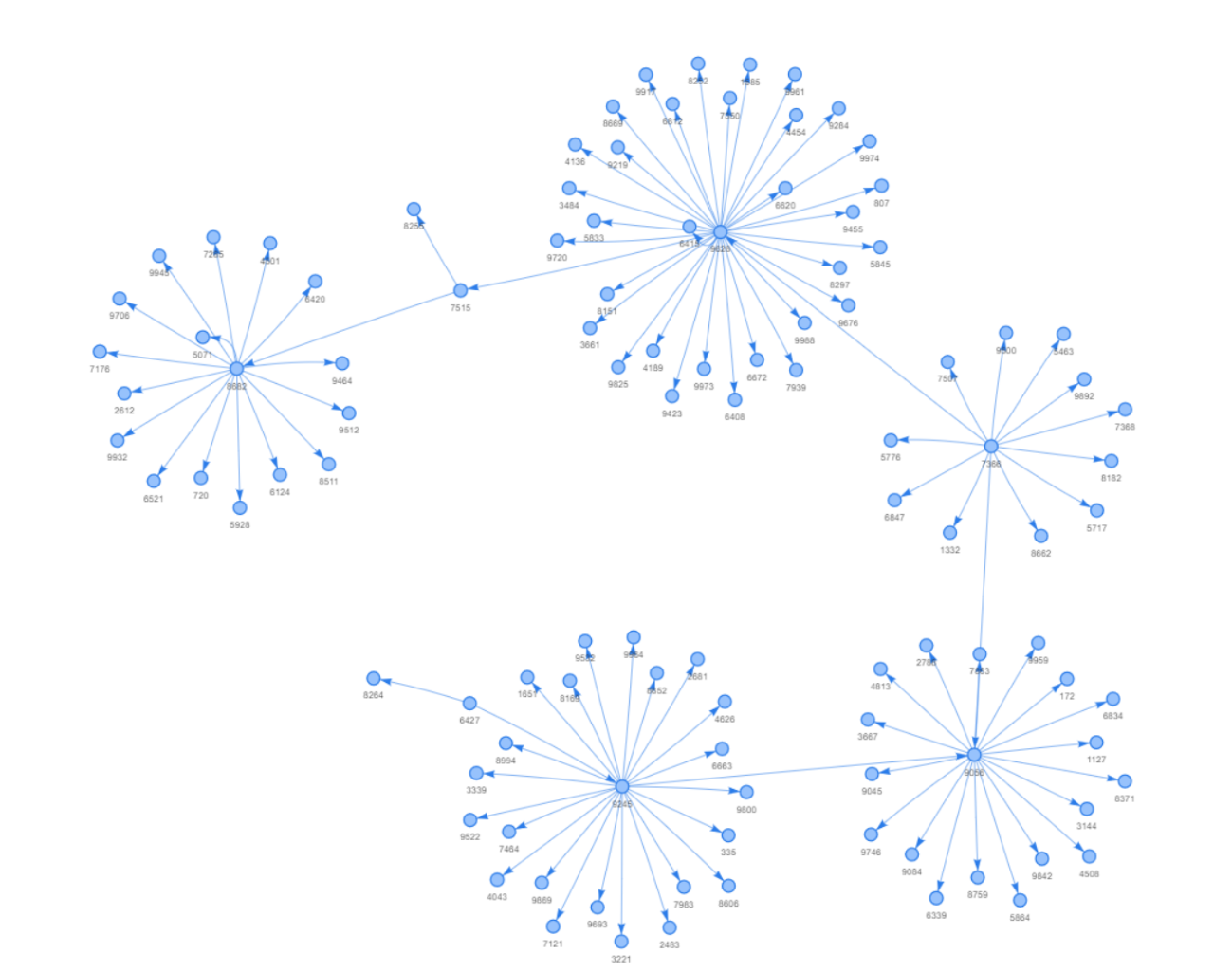
Untuk memvisualisasikan grafik jaringan menggunakan pyvis, pertama-tama kita perlu membuat objek pyvis dengan nt = net.Network(). Kemudian kita mengimpor objek jaringan G ke nt dengan nt.from_nx(G). Akhirnya, kita tampilkan grafik dengan nt.show('1_pyvis_default.html').
Perlu diperhatikan bahwa pyvis akan menghasilkan file html interaktif yang memungkinkan kita memindahkan node dengan kursor, yang jauh lebih presentabel daripada grafik networkx.
Kami akan menggunakan pyvis untuk memvisualisasikan grafik jaringan ke depan. Mari buat fungsi show_graph() untuk menampilkan grafik dengan pyvis untuk penggunaan kami nantinya:
Penetapan Atribut Node
Pada bagian sebelumnya, kita telah membuat grafik sederhana, namun akan lebih baik jika kita dapat menampilkan informasi lebih lanjut untuk setiap node seperti nomor akun, berapa banyak akun yang terhubung, dan akun mana yang terhubung. Kita dapat memperbarui kamus atribut node di bawah G untuk memperkaya grafik.
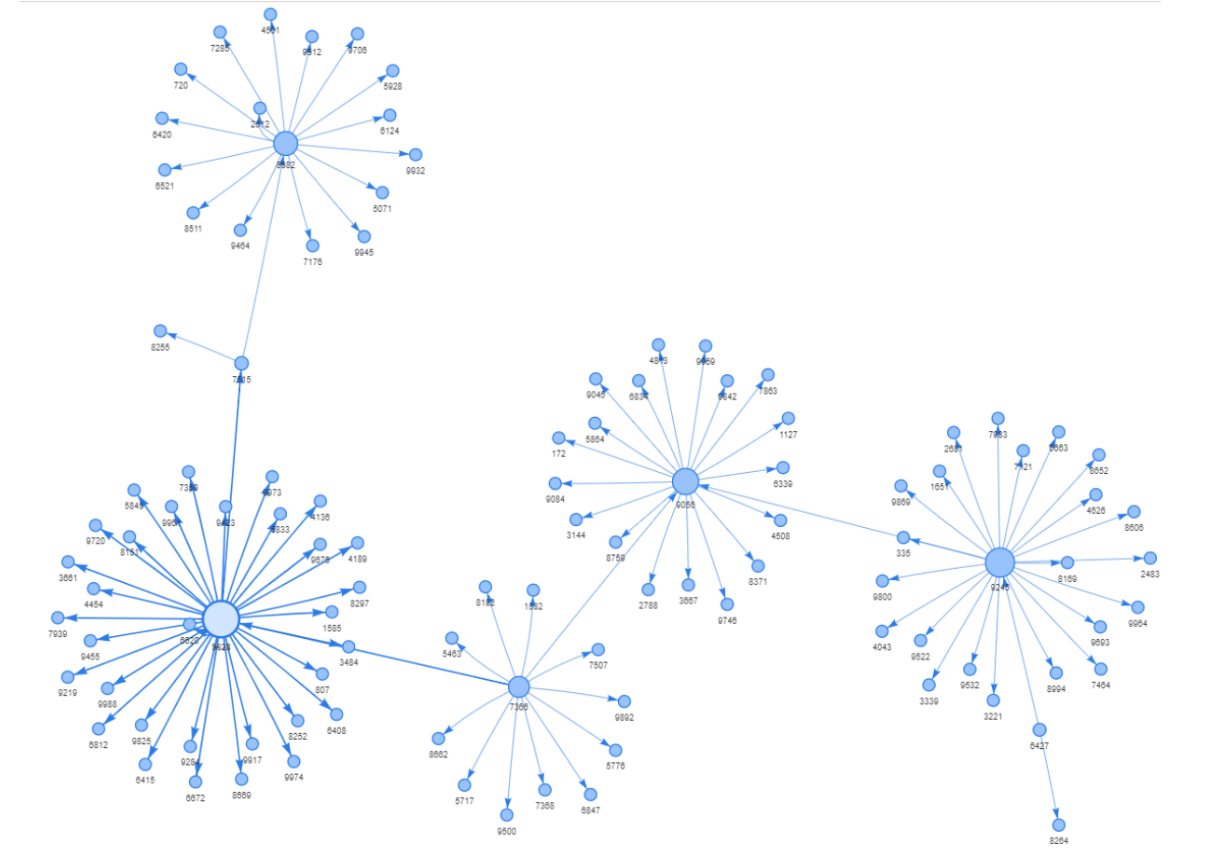
Node Degree sebagai Pengukuran Sentralitas
Pada bagian pengantar, kita telah menyebutkan bahwa analisis jaringan dapat membantu kita mengidentifikasi akun kunci dalam suatu jaringan. Definisi dari "akun kunci" tergantung pada skenario penyelidikan Anda, tetapi taktik umumnya adalah memperlakukan node dengan jumlah koneksi tinggi sebagai akun kunci (seperti node pusat pada grafik di atas). Jumlah koneksi dari setiap node disebut "degree" dalam teori graf.
Cara yang baik untuk menyajikan informasi tersebut adalah dengan menetapkan ukuran node sesuai dengan degree-nya, di mana node dengan degree yang lebih tinggi memiliki ukuran yang lebih besar dan sebaliknya. Untuk melakukannya, kita perlu pertama-tama mendapatkan degree dari setiap node, kemudian menempatkan informasi tersebut sebagai atribut node di bawah G.
Untuk mendapatkan degree dari setiap node, kita dapat menggunakan G.degree, yang akan mengembalikan daftar tuple dengan id node dan degree-nya: Selanjutnya, kita dapat mengubah G.degree menjadi kamus dengan id node sebagai kunci dan degree nya sebagai nilai.
Kemudian kita dapat meneruskan kamus tersebut ke dalam kamus atribut node di bawah G dengan nx.set_node_attributes(). Perlu diingat bahwa kita perlu menetapkan nama atribut sebagai value agar pyvis dapat mengenali itu sebagai ukuran node.
Kita dapat memeriksa G.nodes(data=True) lagi dan Anda akan melihat bahwa node sekarang akan memiliki atribut baru bernama value. Setelah atribut node diperbarui, kita dapat menghasilkan grafik lagi dengan nt.show_graph(). Dan Anda akan melihat bahwa node dengan degree lebih tinggi memiliki ukuran yang lebih besar.
Selain menggunakan degree sebagai pengukuran sentralitas, Anda juga dapat menggunakan pengukuran lain di bawah teori graf (link) seperti eigenvector, closeness, betweenness, dll., atau kriteria apa pun yang dianggap sesuai dalam penyelidikan Anda.
Dari sudut pandang saya, degree adalah indikator yang baik untuk mengidentifikasi anggota kunci dalam kebanyakan kasus.
Tidak peduli pengukuran apa yang telah Anda pilih, prosedurnya serupa di mana Anda harus mendapatkan pengukuran untuk setiap node dalam bentuk kamus, kemudian meneruskan kamus tersebut ke atribut node dengan nama atribut value.
Menampilkan Informasi Node Saat Hover
Pada bagian sebelumnya, kita telah memperbarui ukuran node dengan melewatkan atribut node value. Teknik yang juga berguna adalah menampilkan informasi node saat kita menghover-nya dengan melewatkan atribut title. Sebagai contoh, jika kita ingin menampilkan nomor akun saat menghover, kita dapat dengan mudah:
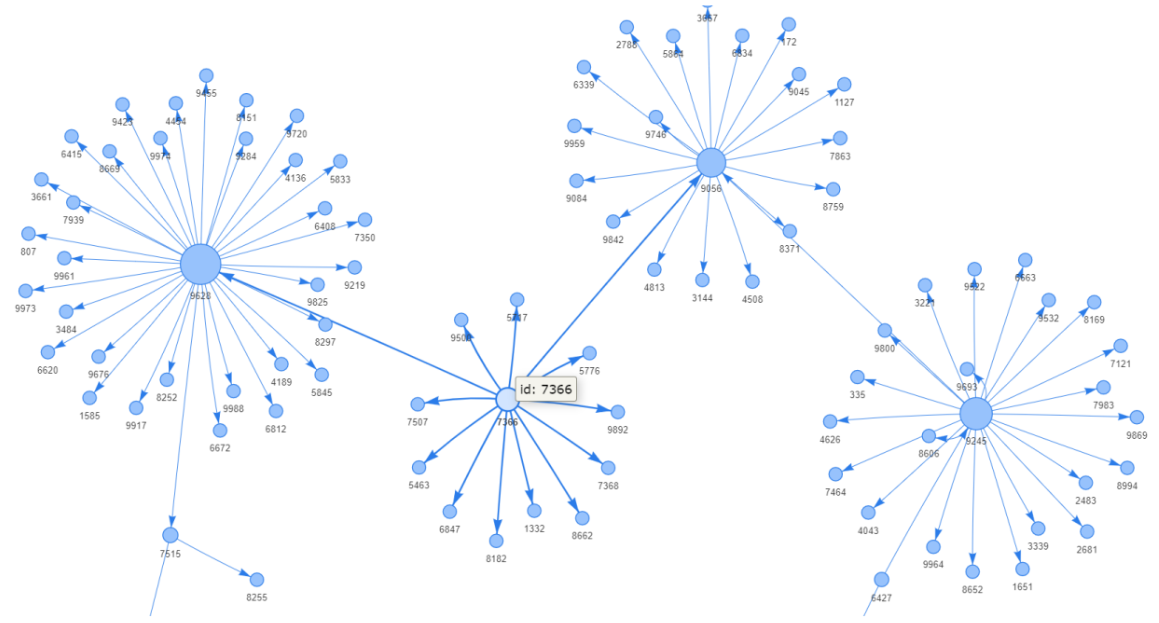
Selain nomor akun, kita dapat menampilkan lebih banyak informasi seperti degree dan daftar node yang terhubung saat menghover, prosedurnya serupa yaitu dengan melewatkan informasi lebih banyak ke atribut title.
Kita telah mendapatkan informasi nomor akun dan degree, namun belum daftar node yang terhubung, yang akan kita perlukan metode G.neighbors() di sini. Metode ini mengembalikan daftar node terhubung (tetangga) untuk setiap node yang diberikan. Sebagai contoh, kode berikut akan memberikan daftar tetangga node 8682.
Sekarang kita dapat membuat kamus daftar tetangga untuk setiap node dan menggabungkannya ke dalam atribut title seperti yang telah kita lakukan sebelumnya. Sekarang kita dapat melihat lebih banyak informasi saat menghover suatu node:
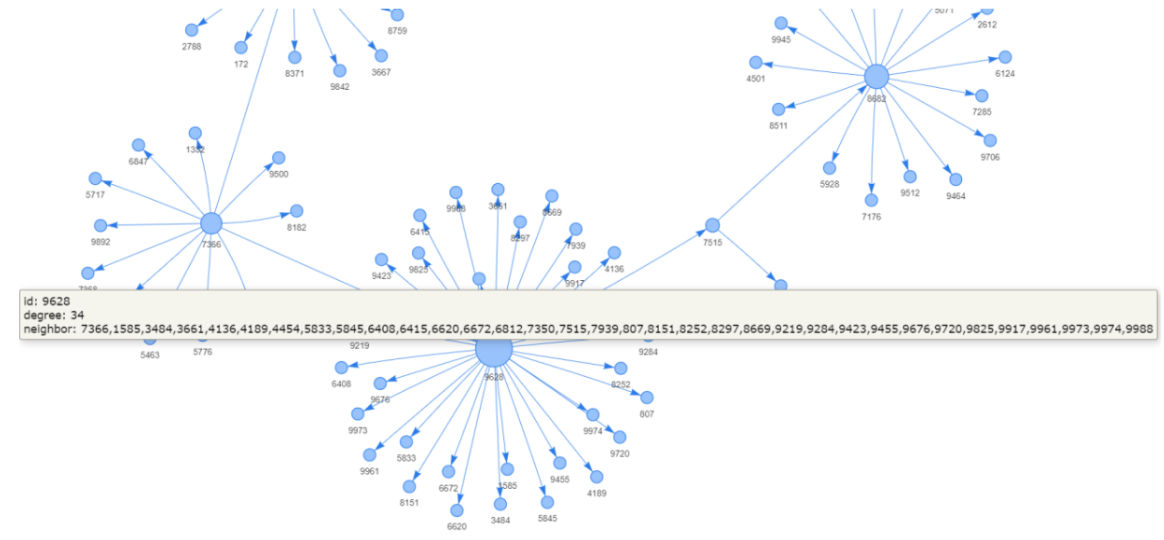
Pada bagian ini, kita telah memperkaya tata letak grafik dengan membedakan ukuran node dan menambahkan informasi node saat hover. Ada lebih banyak pengaturan pengayaan tata letak untuk dieksplorasi dengan pyvis.
Penetapan Atribut Edge
Logika untuk memperkaya tata letak edge identik dengan node, yaitu dengan menetapkan kamus atribut edge di bawah G. Sebagai contoh, kita dapat menyesuaikan lebar edge berdasarkan jumlah transaksi yang diagregasi antara akun, dan menampilkan informasi edge yang detail saat dihover seperti pembayar, penerima, jumlah transaksi yang diagregasi, dan jumlah transaksi yang diagregasi:
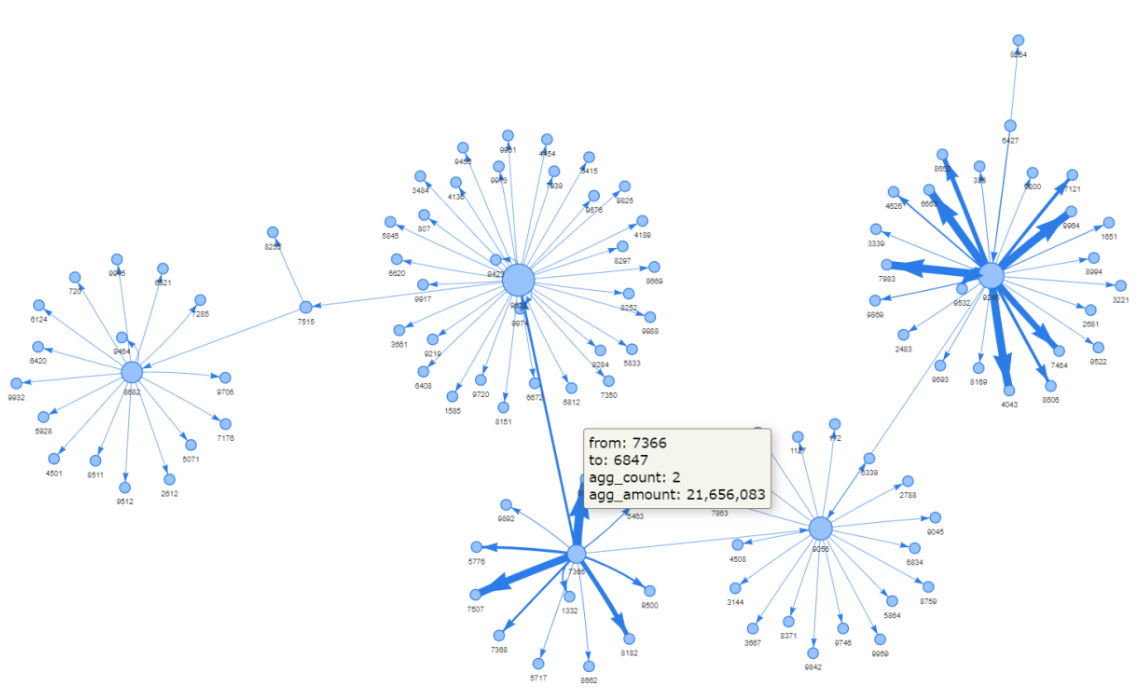
Kita dapat memperoleh kamus atribut edge dengan memperbarui dataframe sumber edge_small. Sama seperti yang telah kita lakukan pada atribut node sebelumnya, value mengendalikan ukuran (lebar) edge dan title mengendalikan informasi yang ditampilkan saat dihover.
Selanjutnya, kita dapat membuat kamus atribut edge untuk value dan title dan meneruskannya ke G sehingga pyvis akan memperbarui tata letak edge sesuai. Kemudian grafik sekarang mampu menampilkan lebih banyak informasi dengan ukuran edge yang berbeda dan informasi hover yang berbeda.
Deteksi Komunitas dengan Dataset Besar
Setelah kita familiar dengan operasi dasar networkx dan pyvis, kita dapat mengeksplorasi struktur jaringan dari dataset yang lebih besar:
Kali ini kita memiliki dataset yang lebih besar dengan 2.000 edge berdasarkan pengambilan sampel acak, dan telah membuat atribut edge berupa nilai dan judul pada awalnya.
Selanjutnya, kita dapat mengimpor dataframe ke networkx seperti yang telah kita lakukan sebelumnya:
Kali ini, kami memperkenalkan parameter baru edge_attr [‘title’,’value’], yang memungkinkan kita mengimpor atribut edge sejak awal dan tidak perlu bermain dengan kode yang rumit seperti pada bagian (g).
Kita dapat memeriksa H.edges(data=True) untuk memverifikasi apakah atribut edge berhasil diimpor ke H. Kita dapat menghasilkan grafik dengan pyvis lagi (Tolong tambahkan baris nt.toggle_physics(False) sebelumnya, jika tidak grafik akan memakan waktu yang sangat lama untuk dimuat):

Sebuah kekacauan! Meskipun pyvis telah melaksanakan tugasnya dengan sempurna untuk menghasilkan grafik jaringan, namun tidak bermakna dari perspektif penyelidikan karena terlalu banyak informasi.
Hal yang sama kemungkinan besar terjadi jika Anda memvisualisasikan semua node yang berasal dari data transaksi di lembaga Anda.
Cara yang lebih baik adalah mengelompokkan node ke dalam kelompok dan menghasilkan grafik jaringan hanya pada kelompok kelompok tertentu. Inilah tempat deteksi komunitas berperan.
Sama seperti pengukuran sentralitas, terdapat berbagai algoritma deteksi komunitas yang dapat kita gunakan untuk membagi node ke dalam kelompok (link).
Namun, dari perspektif analisis aliran dana, pendekatan yang masuk akal adalah mengelompokkan node yang terhubung dalam satu kelompok dan node yang tidak terhubung dalam kelompok lain, sehingga setiap kelompok tidak terhubung, yang dapat diakses dengan menggunakan fungsi nx.connected_components(H).
Dengan connected_components(), networkx menetapkan node ke dalam kelompok yang berbeda sehingga semua kelompok tidak terhubung. Sebagai contoh, kelompok pertama terdiri dari akun ['4333', '6059', '7182', '9703'], kelompok kedua terdiri dari akun ['4297', '5573', '7266', '7369', '9795'] dan seterusnya.
Kita juga dapat memeriksa jumlah total kelompok di H sebagai berikut:
Seperti pengaturan atribut node yang telah kita lakukan sebelumnya, kita juga dapat mengatur nilai dan judul atribut node untuk setiap node di bawah H, namun kali ini kita dapat menambahkan satu elemen lagi yaitu atribut kelompok:
Untuk atribut baru yang terkait dengan pengelompokan node, kita dapat menetapkan atribut bernama kelompok sehingga pyvis akan memberikan warna node dan edge yang berbeda untuk setiap kelompok.
Sekarang setiap node memiliki atribut bernama kelompok dan kita dapat menggunakannya untuk menyaring node untuk pembuatan grafik dengan H.subgraph(). Mari kita hasilkan grafik jaringan untuk kelompok 1 hingga 4:
Sekarang kita memiliki grafik jaringan yang menunjukkan kelompok-kelompok dengan warna yang berbeda!
Identifikasi Aliran Dana End-to-End dari Node Tertentu
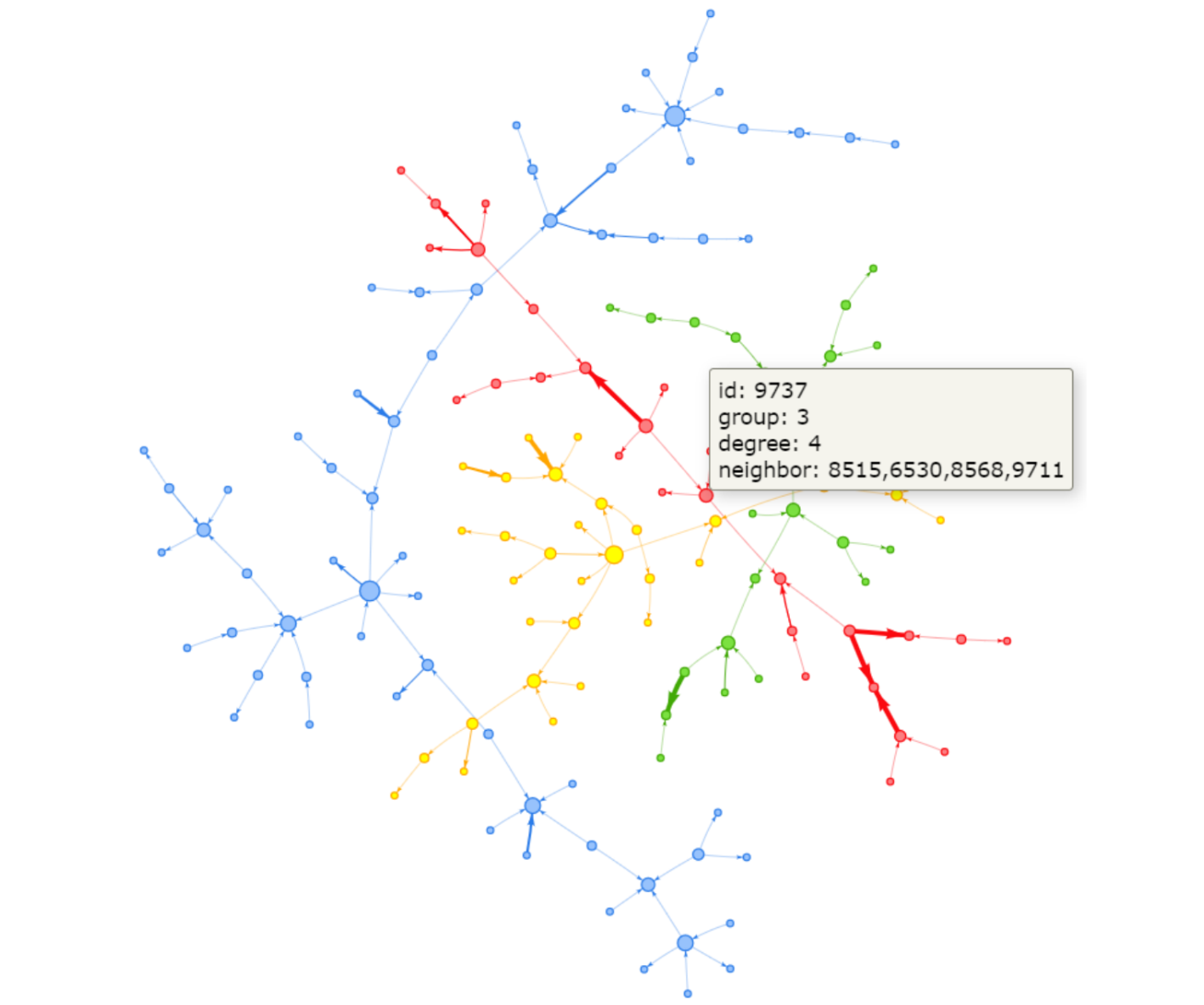
Pada bagian sebelumnya, kami telah menyaring graf jaringan menggunakan nomor grup dengan H.subgraph(). Kode tersebut dapat diperluas lebih lanjut untuk menampilkan graf jaringan dari node tertentu dan node yang terhubung dengannya. Mari kita ambil contoh kita tertarik pada aliran dana end-to-end dari nomor akun 9989:
Ini adalah penggunaan paling kuat dalam penyelidikan AML (Anti Money Laundering) yang memungkinkan Anda mengidentifikasi semua akun terkait dari perspektif end-to-end, dimulai dari node tertentu.
Kita juga dapat menyorot node input 9989 dengan mengubah bentuknya, gambar, dan atribut warna.
Pembahasan (Project Overview)
Salah satu tantangan umum dalam analisis jaringan adalah menentukan periode peninjauan yang tepat. Pengambilan periode yang lebih lama dapat memberikan tampilan jaringan yang lebih komprehensif, tetapi sering kali dengan mengorbankan informasi yang terlalu banyak.
Dalam bagian metode, kami hanya mengambil sampel sebanyak 2.000 edge untuk memastikan grafik jaringan dapat dikelola. Sebenarnya, dalam praktiknya, kita tidak akan membangun jaringan dengan pengambilan sampel acak seperti itu. Sebaliknya, kita dapat mengendalikan ukuran sampel tepi dengan mencoba cakupan jangka waktu yang berbeda, seperti mingguan, bulanan, triwulanan, tahunan, atau lainnya.
Untuk menentukan ukuran sampel yang dapat dikelola (atau ukuran sampel dalam hal ini), kita dapat melakukan pemeriksaan terhadap ukuran kelompok maksimum berdasarkan berbagai ukuran sampel. Sebagai contoh, dengan melakukan simulasi, kita dapat memperoleh gambaran tentang ukuran kelompok maksimum dalam berbagai ukuran sampel. Sebagai ilustrasi, mungkin terdapat 11 node dalam kelompok terbesar jika kita mengambil sampel 1.000 edge, 28 node dalam kelompok terbesar untuk 1.500 sampel edge, dan seterusnya.
Dalam kasus ini, kami memilih ukuran sampel sebanyak 2.000 edge agar analisis jaringan dapat dikelola (dengan kelompok terbesar berisi 64 node). Namun, perlu diingat bahwa tidak ada nilai "optimal" untuk ukuran sampel, dan kita harus menentukan batasnya berdasarkan kebutuhan penyelidikan dan tingkat risiko yang kita tetapkan, mirip dengan menentukan periode "peninjauan kembali transaksi" untuk setiap sampel berdasarkan penyelidikan individu.
Kesimpulan dan Saran (Conclusion & Recommendation)
Kesimpulan
Dalam artikel ini, kami menyajikan contoh implementasi menggunakan Python, khususnya penerapan library NetworkX dan Pyvis, yang membahas ide dasar analisis jaringan dalam konteks AML (Anti Money Laundering), antara lain:
- Membedakan antara analisis aliran dana dan analisis atribut KYC bersama.
- Menghasilkan grafik jaringan dengan menggunakan pandas, networkx, dan pyvis.
- Mengidentifikasi anggota kunci dalam sindikat melalui pengukuran sentralitas.
- Mengidentifikasi kelompok dalam jaringan dengan menggunakan algoritme deteksi komunitas (meskipun pada artikel ini, hanya diterapkan "komponen" dan bukan "algoritme deteksi komunitas", namun konsepnya serupa).
- Mengidentifikasi hubungan end-to-end (analisis hingga ke akar) dengan akun tertentu.
- Menentukan ukuran jaringan yang sesuai dengan membandingkan ukuran kelompok maksimum.
Teori graf sangat bermanfaat untuk tujuan AML dalam mendeteksi kecurigaan dan merangkum temuan. Dalam kasus ini, hanya bagian dasar dari teori tersebut yang diterapkan dalam artikel. Sebagaimana dengan pembelajaran mesin, analisis jaringan masih merupakan tren baru di industri, dan sangat disarankan untuk dipelajari guna meningkatkan pengetahuan sebagai seorang profesional AML.
Rekomendasi
-
Penelitian Lanjutan: Sementara artikel ini memberikan gambaran dasar, disarankan untuk melakukan penelitian lebih lanjut terkait teori graf dan analisis jaringan. Penggunaan algoritma yang lebih kompleks dan penerapan teknik lanjutan dapat meningkatkan keakuratan dan ketajaman analisis jaringan.
-
Pengembangan Model Machine Learning: Integrasikan teknik machine learning untuk meningkatkan kemampuan deteksi dan identifikasi pola-pola yang rumit dalam data transaksi. Model machine learning dapat membantu meningkatkan kecerdasan analisis dan memperluas kemampuan prediktif.
-
Penggunaan Dashboard Interaktif: Gunakan alat visualisasi data yang interaktif atau dashboard untuk memungkinkan pengguna secara efektif mengeksplorasi dan menganalisis data. Ini dapat membantu dalam penyajian temuan secara intuitif kepada pengambil keputusan.
-
Pemantauan Berkala dan Pembaruan Model: Selalu lakukan pemantauan berkala terhadap model dan analisis yang digunakan. Selain itu, pastikan model dan teknik analisis jaringan diperbarui secara berkala sesuai dengan perubahan dalam tren kejahatan keuangan.
-
Pemantauan Regulasi: Tetap memantau perubahan dalam regulasi terkait AML dan keamanan keuangan. Pastikan bahwa sistem dan prosedur yang digunakan selalu mematuhi standar regulasi yang berlaku.
-
Evaluasi dan feedback user: Lakukan evaluasi secara berkala dan dapatkan umpan balik dari pengguna. Ini membantu dalam memahami efektivitas sistem dan memungkinkan peningkatan berkelanjutan.
bagikan
ARTIKEL TERKAIT




Follow Us
© 2026 Purwadhika Digital Technology School All Rights Reserved Owned by PT Purwadhika Kirana Nusantara